Este post no tiene intención de discutir qué layout podría ser mejor en términos de
eficiencia o esfuerzo. Hay una cantidad considerable de grandes artículos relacionados
con todo el análisis a través de diferentes layouts, e incluso herramientas para ingerir texto
y estimar el esfuerzo de escribir el texto para varios layouts.
Encontrarás este artículo más útil si ya decidiste cambiar a Colemak, y
hacerlo tu layout principal. Personalmente, he encontrado muy cómodo escribir
en Dvorak, aunque hay algunas ventajas en Colemak respecto a compatibilidad de atajos
entre otros beneficios que me hicieron hacer la elección. Puedes leer una comparación
muy interesante en este post de Xahlee.
¿Por qué el sampling es importante y de qué necesitas estar consciente?
Cuando lidias con cantidades muy grandes de datos, probablemente quieras ejecutar tus
consultas solo para un conjunto de datos más pequeño en tus tablas actuales. Especialmente si tu conjunto de datos
no cabe en RAM.
MergeTree es el primer y más avanzado motor en Clickhouse que querrás probar.
Soporta indexación por Clave Primaria y es obligatorio tener una columna de tipo Date
(usada para particionamiento automático).
Si has oído sobre Clickhouse y te estás preguntando cómo probar con tus datos residiendo en Redshift, aquí hay un comando
que te mostrará algunos consejos para acelerarte.
Actualización (4 de julio): Hay una serie de posts sobre comparaciones Clickhouse vs Redshift, el primer post es este.
La forma estándar de mover tus datos fuera de Redshift es usando el comando UNLOAD,
que empuja la salida a archivos S3. No sorprendentemente, Redshift no soporta
COPY (<query>) TO STDOUT, lo que podría hacer la vida más fácil (ya que está
basado en Postgres versión 8.0.2, bastante antiguo). Información sobre esto, aquí.
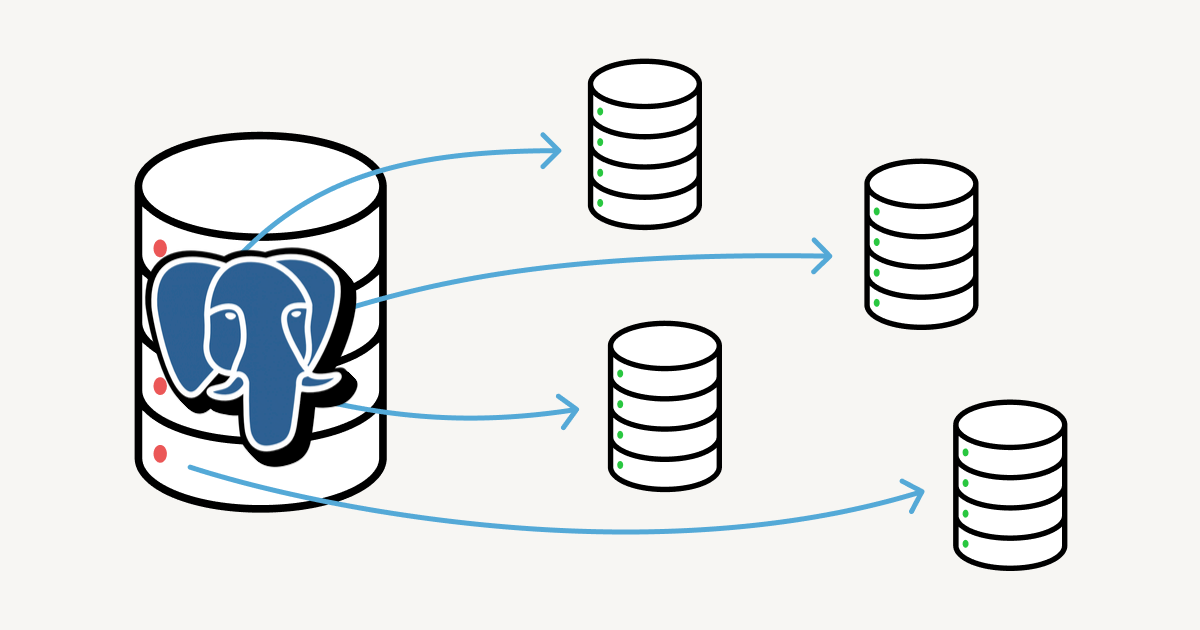
En el concepto actual, vamos a combinar herencia de tablas foráneas con
la extensión postgres_fdw, ambas siendo características ya disponibles desde la versión 9.5.
El particionamiento entre nodos permite una mejor localidad de datos y un modelo más escalable
que mantener particiones locales. Dicho esto, los datos se dividirán en varios
nodos y se organizarán usando una clave particular, que determinará en qué shard
se asignarán los datos. Para el POC actual, vamos a especificar el shardKey
, que es un tipo simple char(2).
En el concepto actual, vamos a combinar herencia de tablas foráneas con
la extensión postgres_fdw, ambas siendo características ya disponibles desde la versión 9.5.
El particionamiento entre nodos permite una mejor localidad de datos y un modelo más escalable
que mantener particiones locales. Dicho esto, los datos se dividirán en varios
nodos y se organizarán usando una clave particular, que determinará en qué shard
se asignarán los datos. Para el POC actual, vamos a especificar el shardKey
, que es un tipo simple char(2).
Apache Kafka y Postgres: Capacidades de transacción y reportes
Apache Kafka es una plataforma de streaming distribuida bien conocida para procesamiento de datos
y mensajería consistente. Te permite centralizar consistentemente streams de datos para
varios propósitos consumiéndolos y produciéndolos.
Uno de los ejemplos de una buena implementación, es la implementación del pipeline de datos de Mozilla,
particularmente ya que muestra Kafka como un punto de entrada del flujo de datos. Esto te permite conectar
nuevos almacenes de datos debajo de su stream, facilitando el uso de diferentes formatos de almacenamiento de datos (
como DRBMS o Document, etc. ) para recuperar y escribir datos eficientemente.