Inyección de datos multi-fuente a Postgres RDS con soporte de encriptación y FTS
Búsqueda compatible con HIPAA
Series: Postgres

Patrocinado: Pythian Inc.
KMS/RDS
El POC en este artículo fue desarrollado antes del lanzamiento del servicio de gestión de claves para RDS.
Desaconsejo totalmente usar el enfoque actual para encriptar datos. Usa REST.
Introducción
He estado tratando con un problema que llegó a mi escritorio de personas de la comunidad, respecto a RDS y reglas HIPAA. Había un escenario confuso sobre si PostgreSQL estaba usando FTS y encriptación en RDS. Hay muchos detalles respecto a la arquitectura, sin embargo creo que no será necesario profundizar muy profundamente para entender los conceptos básicos del motivo del presente artículo.
Las reglas HIPAA son complejas y si necesitas lidiar con ellas, probablemente necesitarás pasar por una lectura cuidadosa.
tl;dr? nos dicen que almacenemos datos encriptados en servidores que no están en las instalaciones.
Y ese es el caso de RDS. Sin embargo, todas las comunicaciones están encriptadas usando
protocolo SSL, pero no es suficiente para cumplir con las reglas HIPAA.
Los recursos de CPU en RDS son caros y no estables a veces, lo que hace que las características de encriptación y
FTS no sean muy adecuadas para este tipo de servicio. No digo que
no puedas implementarlas, solo ten en cuenta que una CPU estándar contra vCPU podría
tener mucha diferencia. Si quieres hacer benchmark de tu CPU local contra vCPU de RDS,
puedes ejecutar la siguiente consulta dentro de psql en ambas instancias:
\o /dev/null
\timing
SELECT convert_from(
pgp_sym_decrypt_bytea(
pgp_sym_encrypt_bytea('Text to be encrypted using pgp_sym_decrypt_bytea' || gen_random_uuid()::text::bytea,'key', 'compress-algo=2'),
'key'),
'SQL-ASCII')
FROM generate_series(1,10000);
Hay muchas cosas y funciones que puedes combinar del paquete pgcrypto
(verás que el repositorio contempla todas ellas).
Intentaré publicar otro blog post respecto a este tipo de benchmarks. Mientras tanto,
esta consulta debería ser suficiente para tener una idea aproximada de la diferencia de rendimiento
entre la instancia RDS vCPU y tus CPUs del servidor.
Conceptos básicos de arquitectura
Para este POC vamos a almacenar FTS y claves GPG localmente, en una instancia PostgreSQL simple y, usando un trigger, encriptar y subir transparentemente a RDS usando el FDW estándar (Foreign Data Wrappers).
Ten en cuenta que la comunicación RDS ya está encriptada vía SSL cuando los datos fluyen entre servidor/cliente. Es importante aclarar esto, para evitar confusiones entre encriptación de comunicación y almacenar datos encriptados.
El trigger simple dividirá los datos no encriptados entre una tabla local almacenando
en una columna tsvector (jsonb en el TODO), encriptará y empujará los datos encriptados
a RDS usando FDW (el paquete postgres_fdw estándar).
Una vista de vuelo simple de la idea se puede observar en la imagen a continuación.
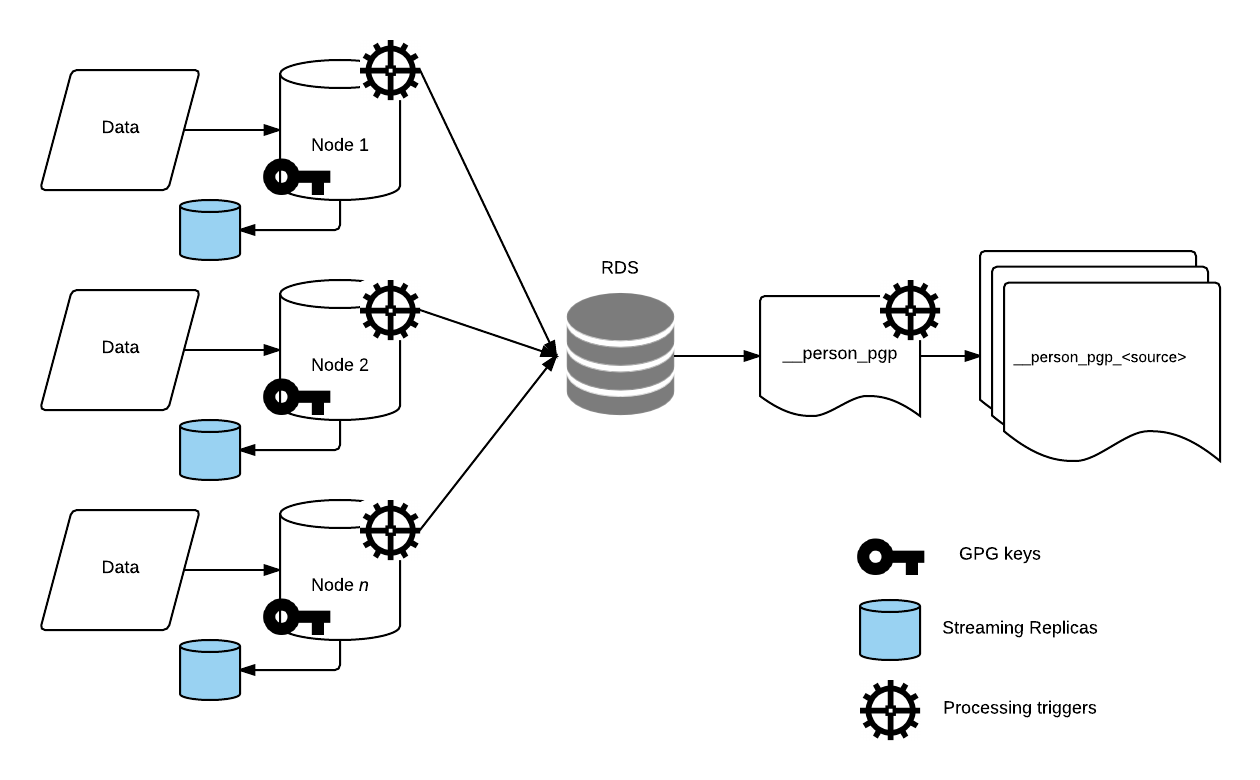
Estructura RDS y estructura local reflejada con FDW
La estructura del esquema de la instancia RDS contiene una tabla padre, un trigger de particionamiento y su trigger:
CREATE SCHEMA enc_schema;
SET search_path TO enc_schema;
-- Encriptando localmente, por eso no necesitamos referenciar la clave aquí.
CREATE TABLE enc_schema.__person__pgp
(
id bigint,
source varchar(8),
partial_ssn varchar(4), -- Campo no encriptado para otros propósitos de búsqueda rápida
ssn bytea,
keyid varchar(16),
fname bytea,
lname bytea,
description bytea,
auth_drugs bytea, -- Este es un vector de texto encriptado
patology bytea,
PRIMARY KEY(id,source)
);
CREATE INDEX ON enc_schema.__person__pgp (partial_ssn);
CREATE OR REPLACE FUNCTION basic_ins_trig() RETURNS trigger LANGUAGE plpgsql AS $basic_ins_trig$
DECLARE
compTable text := TG_RELID::regclass::text ;
childTable text := compTable || '_' || NEW.source ;
statement text := 'INSERT INTO ' || childTable || ' SELECT (' || QUOTE_LITERAL(NEW) || '::' || compTable || ').*' ;
createStmt text := 'CREATE TABLE ' || childTable ||
'(CHECK (source =' || quote_literal(NEW.source) || ')) INHERITS (' || compTable || ')';
indexAdd1 text := 'CREATE INDEX ON ' || childTable || '(source,id)' ;
indexAdd2 text := 'CREATE INDEX ON ' || childTable || '(source,ssn)' ;
BEGIN
BEGIN
EXECUTE statement;
EXCEPTION
WHEN undefined_table THEN
EXECUTE createStmt;
EXECUTE indexAdd1;
EXECUTE indexAdd2;
EXECUTE statement;
END;
RETURN NULL;
END;
$basic_ins_trig$;
CREATE TRIGGER part_person_pgp BEFORE INSERT ON __person__pgp
FOR EACH ROW EXECUTE PROCEDURE basic_ins_trig() ;
No vamos a usar la columna partial SSN en los ejemplos, pero la encontré muy útil para
hacer búsquedas RDS sobre datos encriptados sin caer en la necesidad de desencriptar sobre la marcha el SSN.
Los últimos 4 dígitos del SSN no proporcionan información útil si se roban.
También, la magia de la inyección de datos multi-fuente viene de la clave compuesta usando un bigint y una etiqueta de fuente.
Básicamente, puedes pensar en los nodos locales como proxies. Puedes insertar datos en cada nodo, pero los datos apuntarán a la instancia RDS.
Si estás planeando gestionar grandes cantidades de datos, puedes particionar la tabla en RDS, permitiendo una mejor organización para la gestión de datos.
No verás índices sobre datos encriptados
Estructura de nodos locales:
CREATE DATABASE fts_proxy; -- conectar usando \c fts_proxy en psql
-- La salsa
CREATE EXTENSION postgres_fdw;
CREATE EXTENSION pgcrypto;
CREATE SERVER RDS_server
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host 'dbtest1.chuxsnuhtvgl.us-east-1.rds.amazonaws.com', port '5432', dbname 'dbtest');
CREATE USER MAPPING FOR postgres
SERVER RDS_server
OPTIONS (user 'dbtestuser', password '<shadowed>');
CREATE FOREIGN TABLE __person__pgp_RDS
(
id bigint,
source varchar(8),
partial_ssn varchar(4), -- Campo no encriptado para otros propósitos de búsqueda rápida
ssn bytea,
keyid varchar(16),
fname bytea,
lname bytea,
description bytea,
auth_drugs bytea, -- Este es un vector de texto encriptado
patology bytea
)
SERVER RDS_server
OPTIONS (schema_name 'enc_schema', table_name '__person__pgp');
Misma tabla. Cada vez que queramos tratar con la tabla RDS, lo haremos usando la tabla __person__pgp_RDS, que es solo una tabla de mapeo. Podemos consultar esta tabla como cualquier otra tabla usual.
Para propósitos de prueba, también creé una tabla con la misma estructura que la anterior con
el nombre de tabla __person_rds_RDS_URE y agregué la opción use_remote_estimate 'true'.
Cuando está habilitado, postgres_fdw obtiene el conteo de filas y estimaciones del servidor remoto.
Insertando claves localmente
Solo para evitar un artículo extendido, omitiré los comandos de creación de claves GPG aquí. Por favor sigue las instrucciones en el enlace en la sección de referencia sobre claves.
Podemos insertar las claves de varias formas, pero encontré muy conveniente usar características de psql
para hacerlo. Una vez que las claves están en su lugar puedes usar el comando \lo_import:
postgres=# \lo_import /var/lib/postgresql/9.4/main/private.key
lo_import 33583
postgres=# \lo_import /var/lib/postgresql/9.4/main/public.key
lo_import 33584
Los siguientes pasos son muy directos. En un escenario real, probablemente no querrás subir claves privadas a la tabla, solo por propósitos prácticos de este artículo voy a hacerlo (solo para desencriptar datos en la consulta SELECT).
pgp_key_iddevolverá la misma clave sin importar si usas clave privada o pública.
CREATE TABLE keys (
keyid varchar(16) PRIMARY KEY,
pub bytea,
priv bytea
);
INSERT INTO keys VALUES ( pgp_key_id(lo_get(33583)) ,lo_get(33584), lo_get(33583));
Dividiendo datos a FTS, encriptar y empujar a RDS
Ahora, aquí es cuando comienza la parte complicada. Vamos a lograr algunas funcionalidades:
- Vamos a simular routing usando herencia en los registros FTS. Eso nos permitirá dividir datos como queramos y, replicar usando la característica Logical Decoding entre los nodos. No incluiré esto en el artículo actual solo para evitar que sea extenso.
- Vamos a encriptar usando la clave que seleccionamos en la consulta de inserción. Si quieres una clave por tabla, encontrarás más fácil hardcodear el id de clave en
_func_get_FTS_encrypt_and_push_to_RDS. - Una vez que los registros están encriptados, la función insertará esos registros en la tabla foránea (RDS).
- Al consultar la tabla FTS, podremos determinar la fuente (algo como la técnica
routing, encontrarás esto familiar si jugaste con ElasticSearch). Eso nos permite hacer la búsqueda FTS transparente para la aplicación, apuntando siempre a la tabla padre. :dogewow:
¿No es genial Postgres? :o
Estructuras de tabla FTS
-- Tabla padre
CREATE TABLE local_search (
id bigint PRIMARY KEY,
_FTS tsvector
);
CREATE INDEX fts_index ON local_search USING GIST(_FTS);
-- Tabla hija, sufijo local_search_<source>
CREATE TABLE local_search_host1 () INHERITS (local_search);
CREATE INDEX fts_index_host1 ON local_search_host1 USING GIST(_FTS);
Haciendo esto, evitas tener una columna con un valor constante en la tabla, consumiendo espacio innecesario. Puedes tener con este método, diferentes nombres y tablas a través del cluster, pero siempre usando la misma consulta contra local_search. Puedes map/reduce los datos si quieres a través de los nodos, con la misma consulta.
No es necesario tener solo 1 fuente o ruta por nodo. El único requisito para esto es tener diferentes rutas por nodo (combinar fuente y ruta podría aumentar la complejidad, sin embargo es posible).
Código principal
CREATE SEQUENCE global_seq INCREMENT BY 1 MINVALUE 1 NO MAXVALUE;
CREATE TABLE __person__pgp_map
(
keyid varchar(16),
source varchar(8),
ssn bigint,
fname text,
lname text,
description text,
auth_drugs text[], -- Este es un vector de texto encriptado
patology text
);
CREATE OR REPLACE FUNCTION _func_get_FTS_encrypt_and_push_to_RDS() RETURNS "trigger" AS $$
DECLARE
secret bytea;
RDS_MAP __person__pgp_RDS%ROWTYPE;
FTS_MAP local_search%ROWTYPE;
BEGIN
SELECT pub INTO secret FROM keys WHERE keyid = NEW.keyid;
RDS_MAP.source := NEW.source;
RDS_MAP.fname := pgp_pub_encrypt(NEW.fname, secret);
RDS_MAP.lname := pgp_pub_encrypt(NEW.lname, secret);
RDS_MAP.auth_drugs := pgp_pub_encrypt(NEW.auth_drugs::text, secret);
RDS_MAP.description := pgp_pub_encrypt(NEW.description, secret);
RDS_MAP.patology := pgp_pub_encrypt(NEW.patology, secret);
RDS_MAP.ssn := pgp_pub_encrypt(NEW.ssn::text, secret);
RDS_MAP.partial_ssn := right( (NEW.ssn)::text,4);
RDS_MAP.id := nextval('global_seq'::regclass);
RDS_MAP.keyid := NEW.keyid;
FTS_MAP.id := RDS_MAP.id;
FTS_MAP._FTS := (setweight(to_tsvector(NEW.fname) , 'B' ) ||
setweight(to_tsvector(NEW.lname), 'A') ||
setweight(to_tsvector(NEW.description), 'C') ||
setweight(to_tsvector(NEW.auth_drugs::text), 'C') ||
setweight(to_tsvector(NEW.patology), 'D')
) ;
-- Ambas tablas contienen mismo id,source
INSERT INTO __person__pgp_RDS SELECT (RDS_MAP.*);
EXECUTE 'INSERT INTO local_search_' || NEW.source || ' SELECT (' || quote_literal(FTS_MAP) || '::local_search).* ';
RETURN NULL;
END;
$$
LANGUAGE plpgsql;
CREATE TRIGGER trigger_befInsRow_name_FTS
BEFORE INSERT ON __person__pgp_map
FOR EACH ROW
EXECUTE PROCEDURE _func_get_FTS_encrypt_and_push_to_RDS();
Esta función hace todo. Inserta los datos en RDS y divide los datos en la tabla hija FTS correspondiente. Por propósitos de rendimiento, no quise capturar excepciones en el momento de inserción (si la tabla hija no existe, p.ej.), pero también puedes agregar esta característica con un bloque de excepción como sigue:
BEGIN
EXECUTE 'INSERT INTO local_search_' || NEW.source || ' SELECT (' || quote_literal(FTS_MAP) || '::local_search).* ';
EXCEPTION WHEN undefined_table THEN
EXECUTE 'CREATE TABLE local_search_' || NEW.source || '() INHERITS local_search';
END;
Lo mismo se puede hacer sobre la tabla foránea. Más información en “Class HV — Foreign Data Wrapper Error (SQL/MED)” (HV00R -fdw_table_not_found).
Revisa “Appendix A. PostgreSQL Error Codes” en el manual oficial para referencias sobre códigos de error.
Insertando datos
En el momento de inserción, vamos a empujar datos a través de una tabla de mapeo. La razón de esto es que todos los datos encriptados se almacenan en tipo de datos bytea, y queremos tener consultas claras en su lugar.
Una consulta de datos aleatorios se verá como:
INSERT INTO __person__pgp_map
SELECT
'host1', -- source: host1
-- Puedes hacer esto mejor obteniendo estos datos de una ubicación
-- persistente
'76CDA76B5C1EA9AB',
round(random()*1000000000),
('{Romulo,Ricardo,Romina,Fabricio,Francisca,Noa,Laura,Priscila,Tiziana,Ana,Horacio,Tim,Mario}'::text[])[round(random()*12+1)],
('{Perez,Ortigoza,Tucci,Smith,Fernandez,Samuel,Veloso,Guevara,Calvo,Cantina,Casas,Korn,Rodriguez,Ike,Baldo,Vespi}'::text[])[round(random()*15+1)],
('{some,random,text,goes,here}'::text[])[round(random()*5+1)] ,
get_drugs_random(round(random()*10)::int),
('{Anotia,Appendicitis,Apraxia,Argyria,Arthritis,Asthma,Astigmatism,Atherosclerosis,Athetosis,Atrophy,Abscess,Influenza,Melanoma}'::text[])[round(random()*12+1)]
FROM generate_series(1,50) ;
¿Viste el comentario interno? Bueno, probablemente quieras dividir por customer o cualquier otro alias. Estoy usando este texto hardcodeado feo solo para evitar un artículo largo.
También, si quieres evitar hardcodear tanto como sea posible, puedes considerar usar una función que devuelva el nombre del host o etiqueta de routing.
Consultando los datos
¡Casi terminamos! Ahora podemos hacer algunas consultas. Aquí hay algunos ejemplos:
Limitando las coincidencias:
# SELECT convert_from(pgp_pub_decrypt(ssn::text::bytea, ks.priv,''::text)::bytea,'SQL_ASCII'::name)
# FROM __person__pgp_rds as rds JOIN
# keys ks USING (keyid)
# WHERE rds.id IN (
# select id
# from local_search
# where to_tsquery('Asthma | Athetosis') @@ _fts LIMIT 5)
# AND rds.source = 'host1';
source | convert_from
--------+--------------
host1 | 563588056
(1 row)
Todas las coincidencias y verificación doble de dónde vinieron los datos:
# SELECT ls.tableoid::regclass, rds.source,
# convert_from(pgp_pub_decrypt(ssn::text::bytea, ks.priv,''::text)::bytea,'SQL_ASCII'::name)
# FROM local_search ls JOIN
# __person__pgp_rds as rds USING (id),
# keys ks
# WHERE to_tsquery('Asthma | Athetosis') @@ ls._fts;
tableoid | source | convert_from
-------------------+--------+--------------
local_search_host1 | host1 | 563588056
(1 row)
Y, no podemos terminar el artículo sin mostrar cómo usar el ranking (¿viste esas funciones setweight usadas en la función? ¡Lo entendiste!):
# SELECT rds.id,
# convert_from(pgp_pub_decrypt(fname::bytea, ks.priv,''::text)::bytea,'SQL_ASCII'::name),
# convert_from(pgp_pub_decrypt(lname::bytea, ks.priv,''::text)::bytea,'SQL_ASCII'::name),
# ts_rank( ls._FTS, query ) as rank
# FROM local_search ls JOIN
# __person__pgp_rds as rds ON (rds.id = ls.id AND rds.source = 'host1') JOIN
# keys ks USING (keyid),
# to_tsquery('Mario | Casas | (Casas:*A & Mario:*B) ') query
# WHERE
# ls._FTS @@ query
# ORDER BY rank DESC;
id | convert_from | convert_from | rank
----+--------------+--------------+----------
43 | Mario | Casas | 0.425549
61 | Ana | Casas | 0.303964
66 | Horacio | Casas | 0.303964
(3 rows)
Recuerda, piensa que esta consulta está haciendo FTS, desencriptación y ranking en solo una consulta, sobre un servidor local y un servidor remoto. ¡No puedes decir que PostgreSQL no es lo suficientemente hipster!
No puedo continuar el artículo sin mostrar el plan de consulta ejecutado por el host local (usando buffers, analyze y opciones verbose):
EXPLAIN (buffers,verbose,analyze) SELECT rds.id,
convert_from(pgp_pub_decrypt(fname::bytea, ks.priv,''::text)::bytea,'SQL_ASCII'::name),
convert_from(pgp_pub_decrypt(lname::bytea, ks.priv,''::text)::bytea,'SQL_ASCII'::name),
ts_rank( ls._FTS, query ) as rank
FROM local_search ls JOIN
__person__pgp_rds as rds ON (rds.id = ls.id AND rds.source = 'host1') JOIN
keys ks USING (keyid),
to_tsquery('Mario | Casas | (Casas:*A & Mario:*B) ') query
WHERE
ls._FTS @@ query
ORDER BY rank DESC;
....
-> Materialize (cost=100.00..117.09 rows=3 width=122) (actual time=62.946..62.971 rows=50 loops=9)
Output: rds.id, rds.fname, rds.lname, rds.keyid
-> Foreign Scan on public.__person__pgp_rds rds (cost=100.00..117.07 rows=3 width=122) (actual time=566.495..566.520 rows=50 loops=1)
Output: rds.id, rds.fname, rds.lname, rds.keyid
Remote SQL: SELECT id, keyid, fname, lname FROM enc_schema.__person__pgp WHERE ((source = 'host1'::text))
...
Planning time: 4.931 ms
Execution time: 2115.919 ms
(45 rows)
Del extracto del Plan de Consulta anterior, podemos ver que el particionamiento en RDS es transparente para la consulta. El nodo de ejecución a cargo de extraer datos del RDS es el Foreign Scan, que también proporciona la consulta ejecutada remotamente.
Espera un minuto. Parece que el SQL remoto es de alguna manera peligroso de ejecutar. ¡No está usando el id! Hay una razón para eso, y está relacionada con cómo postgres recopila las estadísticas de la tabla foránea. Si uso las estimaciones remotas podemos ver cómo cambia el SQL remoto en el Plan de Consulta:
EXPLAIN (ANALYZE, VERBOSE, BUFFERS) SELECT rds.id,
convert_from(pgp_pub_decrypt(fname::bytea, ks.priv,''::text)::bytea,'SQL_ASCII'::name),
convert_from(pgp_pub_decrypt(lname::bytea, ks.priv,''::text)::bytea,'SQL_ASCII'::name),
ts_rank( ls._FTS, query ) as rank
FROM local_search ls, __person__pgp_rds_URE rds JOIN
keys ks USING (keyid),
to_tsquery('Mario | Casas | (Casas:*A & Mario:*B) ') query
WHERE
rds.id = ls.id
AND rds.source = 'host1'
AND
ls._FTS @@ query
ORDER BY rank DESC;
Plan de Consulta (nodo de ejecución Foreign Scan):
...
-> Foreign Scan on public.__person__pgp_rds_ure rds (cost=100.01..108.21 rows=2 width=1018) (actual time=250.334..250.336 rows=1 loops=31)
Output: rds.id, rds.source, rds.partial_ssn, rds.ssn, rds.keyid, rds.fname, rds.lname, rds.description, rds.auth_drugs, rds.patology
Remote SQL: SELECT id, keyid, fname, lname FROM enc_schema.__person__pgp WHERE ((source = 'host1'::text)) AND (($1::bigint = id))
...
Las tablas foráneas también necesitan que se actualicen las estadísticas locales. En los siguientes ejemplos
hay 3 consultas: usando use_remote_estimate, sin ANALYZE previo y
sin use_remote_estimate y una consulta usando las estimaciones locales (__person_pgp_rds)
después de emitir ANALYZE y sin URE.
fts_proxy=# \o /dev/null
fts_proxy=# SELECT rds.id,
convert_from(pgp_pub_decrypt(fname::bytea, ks.priv,''::text)::bytea,'SQL_ASCII'::name),
convert_from(pgp_pub_decrypt(lname::bytea, ks.priv,''::text)::bytea,'SQL_ASCII'::name),
ts_rank( ls._FTS, query ) as rank
FROM local_search ls, __person__pgp_rds_URE rds JOIN
keys ks USING (keyid),
to_tsquery('Mario | Casas | (Casas:*A & Mario:*B) ') query
WHERE
rds.id = ls.id
AND rds.source = 'host1'
AND
ls._FTS @@ query
ORDER BY rank DESC;
Time: 12299,691 ms
fts_proxy=# SELECT rds.id,
convert_from(pgp_pub_decrypt(fname::bytea, ks.priv,''::text)::bytea,'SQL_ASCII'::name),
convert_from(pgp_pub_decrypt(lname::bytea, ks.priv,''::text)::bytea,'SQL_ASCII'::name),
ts_rank( ls._FTS, query ) as rank
FROM local_search ls, __person__pgp_rds rds JOIN
keys ks USING (keyid),
to_tsquery('Mario | Casas | (Casas:*A & Mario:*B) ') query
WHERE
rds.id = ls.id
AND rds.source = 'host1'
AND
ls._FTS @@ query
ORDER BY rank DESC;
Time: 20249,719 ms
-- DESPUÉS DE ANALYZE en la TABLA FORÁNEA __person_pgp_rds (en el servidor local)
Time: 1656,912 ms
Después de analizar ambas tablas foráneas, la diferencia de tiempo de ejecución se calculó en 11% a favor de usar estimaciones locales.
NOTA sobre UPDATES: es necesario codificar el trigger UPDATE también, para desencriptar, modificar y re-encriptar los datos.
El tipo de datos Json/jsonb está aquí para ayudar
Puedes colapsar todos los datos y usar tipo de datos json en la tabla de mapeo y foránea, permitiéndote evitar el dolor de apuntar y desencriptar datos por columna.
Coloca todas las columnas encriptadas en una columna bytea en RDS. La tabla de mapeo se verá como sigue:
CREATE TABLE __person__pgp_map
(
keyid varchar(16),
source varchar(8),
ssn bigint,
data jsonb
);
En el momento de inserción, solo usa una columna json en lugar de por columna. Ten en cuenta que necesitarás lidiar dentro del contenido json.
Encontré usar esto más fácil para insertar, pero el FTS necesita algo de limpieza para evitar insertar nombres de columnas en el campo _fts en las tablas local_search.
También, para actualizaciones, el tipo de datos jsonb necesitará trabajo extra al extraer atributos.
Funciones adicionales usadas aquí
En la declaración de inserción anterior, verás una función definida por el usuario que obtiene un vector de longitud aleatoria de drogas. Está implementada usando el siguiente código:
CREATE TABLE drugsList ( id serial PRIMARY KEY, drugName text);
INSERT INTO drugsList(drugName) SELECT p.nameD FROM regexp_split_to_table(
'Acetaminophen
Adderall
Alprazolam
Amitriptyline
Amlodipine
Amoxicillin
Ativan
Atorvastatin
Azithromycin
Ciprofloxacin
Citalopram
Clindamycin
Clonazepam
Codeine
Cyclobenzaprine
Cymbalta
Doxycycline
Gabapentin
Hydrochlorothiazide
Ibuprofen
Lexapro
Lisinopril
Loratadine
Lorazepam
Losartan
Lyrica
Meloxicam
Metformin
Metoprolol
Naproxen
Omeprazole
Oxycodone
Pantoprazole
Prednisone
Tramadol
Trazodone
Viagra
Wellbutrin
Xanax
Zoloft', '\n') p(nameD);
CREATE OR REPLACE FUNCTION get_drugs_random(int)
RETURNS text[] AS
$BODY$
WITH rdrugs(dname) AS (
SELECT drugName FROM drugsList p ORDER BY random() LIMIT $1
)
SELECT array_agg(dname) FROM rdrugs ;
$BODY$
LANGUAGE 'sql' VOLATILE;
Referencias
Un tutorial muy increíble sobre FTS para PostgreSQL se puede encontrar aquí.
- Fuente para lista de drogas
- Fuente para enfermedades
- Empezando con claves GPG
- Herramienta de línea de comandos AWS
Discusión en la lista de correo de la comunidad aquí.