Resaltando nuevas características de Postgres 10: Replicación Lógica y Particionamiento.
Y jugando con políticas de retención.
Series: Postgres

¡Hola! En este artículo vamos a explorar dos de las características principales comprometidas en la próxima release de PostgreSQL: Replicación Lógica y Particionamiento. No hace falta decir que estas características aún no están disponibles en la release estable, así que están propensas a cambiar o extenderse.
¡Advertencia publicitaria! El artículo actual es solo un vistazo de la próxima charla Demystifying Logical Replication on PostgreSQL en Percona Live Santa Clara 2017. ¡Consigue tus tickets!
Replicación Lógica
El mecanismo actual de replicación lógica es solo basado en filas. Si estás alrededor del mundo MySQL notarás que el modo statement no está soportado. Si no estás familiarizado con la diferencia entre los modos, TL;DR no importa cuántas filas estén involucradas en la consulta fuente, se enviarán como filas individuales a los slaves. Es decir, una declaración única de múltiples filas como un INSERT en la fuente producirá una entrada por fila modificada .
Esto es algo que puedes querer tener en consideración al hacer cargas masivas, ya que hay otras herramientas/técnicas que podrían ser un mejor ajuste además de hacer stream de todo desde el master usando el stream de replicación lógica.
Generalmente hablando, consiste en tres elementos visibles, también detallados en la imagen a continuación:
- una Publication (fuente)
- una Subscription (consumidor)
- y un Logical Replication Slot
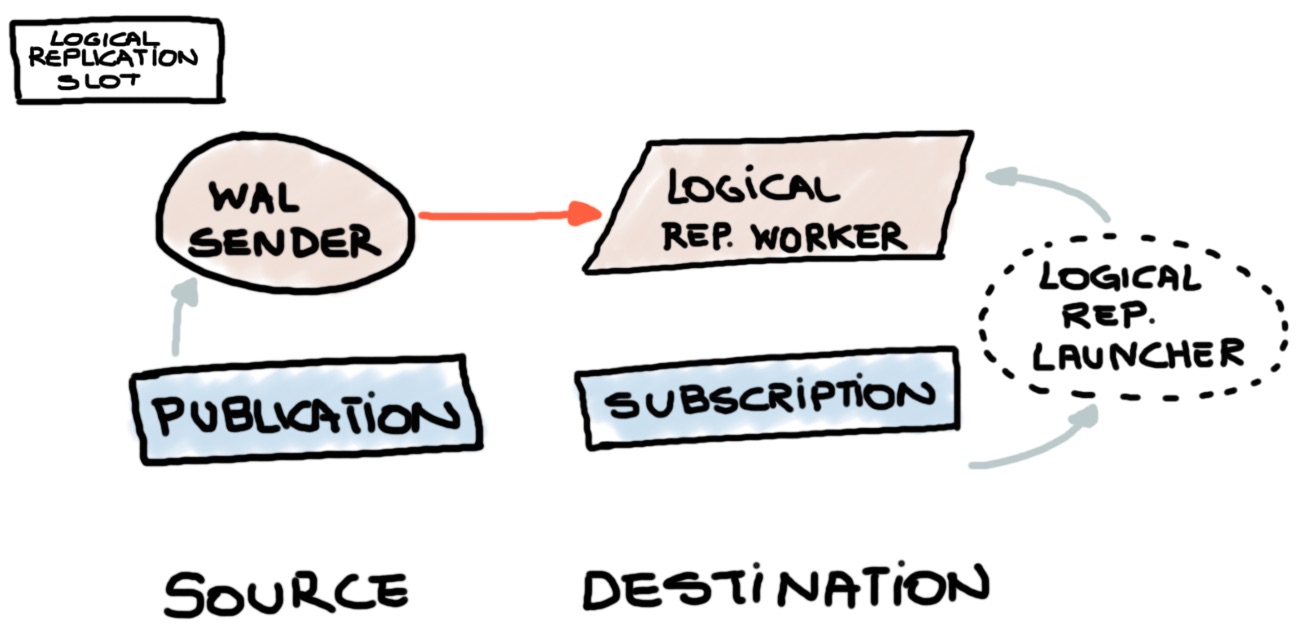
Lo más importante y probablemente lo más complejo es el Logical Replication Slot.
La magia se hace internamente a través del plugin pgoutput, que es la pieza de código a cargo
de traducir los registros WAL (pg_wal) en entradas en el logical log (pg_logical).
El panorama completo puede resumirse así: Los consumidores se suscriben a un único Publisher usando un slot, que contiene el snapshot (LSN) de la base de datos (el punto en el tiempo dado del cluster). El slot proporcionará la información al motor sobre el punto en el tiempo desde el cual los cambios deben replicarse.
En este punto, es importante notar que la característica completa no está completamente comprometida
y se espera contar con una opción WITH COPY DATA en la creación del evento de creación de eventos de suscripción
para sincronizar datos desde la fuente. Actualmente, el parche tiene algunos bugs y está en proceso de revisión.
Aunque todo el tema es interesante, todo lo relacionado con Logical Decoding se omitirá en este artículo. Puedes hacer más que solo replicación Postgres-to-Postgres.
Particionamiento
En las versiones pasadas, era posible alcanzar un enfoque de particionamiento muy flexible combinando herencia y triggers basados en múltiples lenguajes. La implementación actual no permite mezclar herencia y particionamiento pero aún tiene cierta flexibilidad para desacoplar y acoplar particiones, usando una sintaxis explícita.
En el ejemplo actual, vamos a crear tres particiones sin datos, solo para mantener el foco solo en el POC.
POC
El concepto actual funciona alrededor de tener slaves con una política de retención diferente de cada particionamiento replicando cada una en diferentes destinos y filtrando las operaciones DELETE. Como adición, somos capaces de crear una estructura dummy, para apuntar a cada particionamiento externo para reportes o consultas de datos históricos.
El concepto tiene tres tipos de nodos/bases de datos:
- Un proxy (manteniendo solo Foreign Data Wrappers apuntando a tablas hijas en herencia de una tabla dummy)
- Un master (Conteniendo todas las particiones)
- Bases de datos Shard (Solo manteniendo la información de shard correspondiente)
Más o menos, usando los comandos en este artículo, deberías terminar con una imagen como esta:
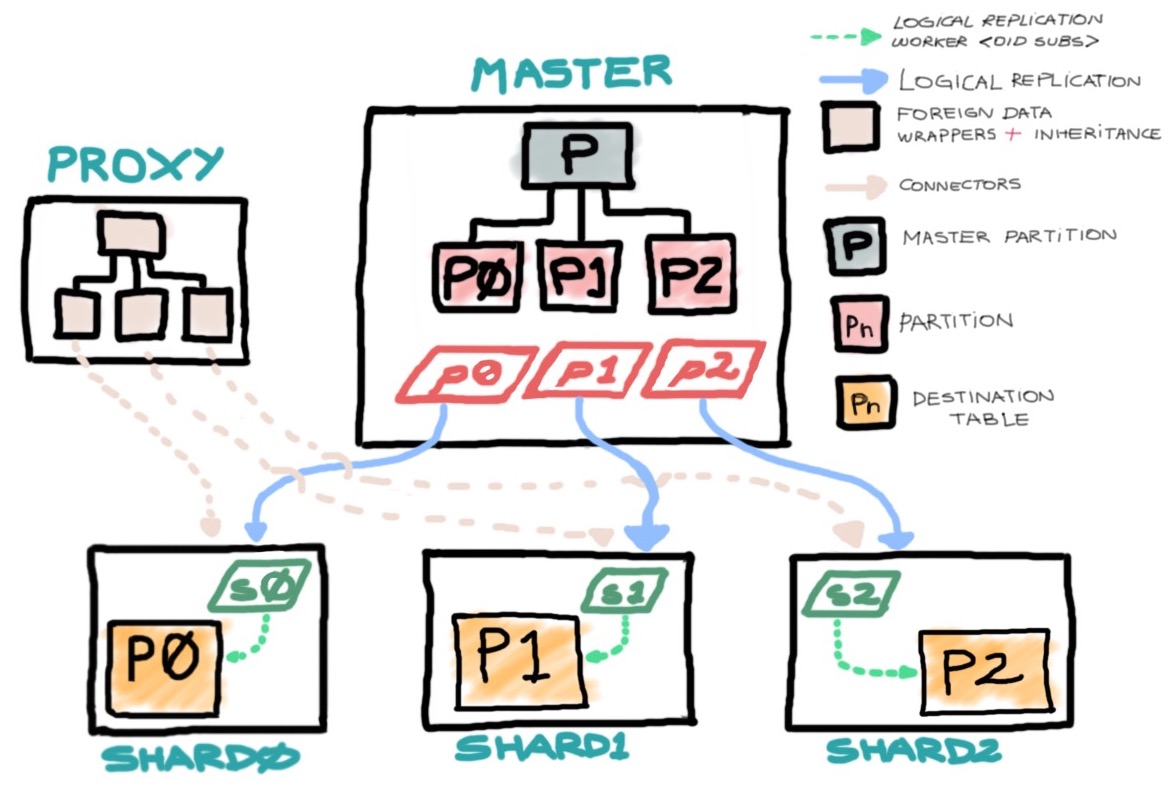
Como probablemente notarás, al eliminar filas en la base de datos fuente y filtrar eventos DELETE en el momento de publicación, terminarás con slaves manteniendo más datos, permitiendo consultas de marcos de tiempo más grandes. Esto es particularmente útil para dividir consultas BI en diferentes capas dependiendo de las especificaciones de rangos de fechas, ahorrando propósitos de almacenamiento en la fuente o manteniendo también un tamaño de tabla más mantenible. Las consultas contra archivo se pueden hacer directamente en los nodos o a través de la implementación proxy mencionada adelante.
Particionamiento en la base de datos fuente/punto de entrada
La base de datos master mantendrá las definiciones y los datos más recientes. El concepto actual, se alimenta de un topic del broker Apache Kafka que está particionado en tres. Vamos a alimentar esta tabla con streams usando el comando COPY. El artículo explicando cómo se hizo esto está aquí.
El DDL de las tablas de la base de datos master actual es:
CREATE TABLE main (group_id char(2), stamp timestamp without time zone DEFAULT now(), payload jsonb) PARTITION BY LIST(group_id);
CREATE TABLE main_shard0 PARTITION OF main
FOR VALUES IN ('P0');
CREATE TABLE main_shard1 PARTITION OF main
FOR VALUES IN ('P1');
CREATE TABLE main_shard2 PARTITION OF main
FOR VALUES IN ('P2');
CREATE INDEX ix_main_shard_p0_key ON main_shard0 (stamp,(payload->>'key'));
CREATE INDEX ix_main_shard_p1_key ON main_shard1 (stamp,(payload->>'key'));
CREATE INDEX ix_main_shard_p2_key ON main_shard2 (stamp,(payload->>'key'));
La columna group_id mantiene el número de partición del topic del cual los datos han
sido consumidos del broker Kafka.
Ahora, es momento de publicarlas dentro del filtrado de eventos correspondiente. En este punto, no hay ningún slot de replicación asociado con las publicaciones:
CREATE PUBLICATION P_main_P0 FOR TABLE main_shard0 WITH (NOPUBLISH DELETE);
CREATE PUBLICATION P_main_P1 FOR TABLE main_shard1 WITH (NOPUBLISH DELETE);
CREATE PUBLICATION P_main_P2 FOR TABLE main_shard2 WITH (NOPUBLISH DELETE);
Por el estado actual de los últimos commits en PostgreSQL, Logical Replication no soporta
filtrado por valor de columna como lo hace la herramienta pglogical. Aunque es posible filtrar por
declaración de evento, que aún es bastante útil para nuestro propósito (NOPUBLISH|PUBLISH) como
se describe arriba.
Creando los nodos
La definición de tabla en los nodos debería ser directa:
CREATE TABLE main_shard0 (group_id char(2), stamp timestamp without time zone, payload jsonb);
Ahora necesitamos crear la SUBSCRIPTION para alimentarse de la PUBLICATION correspondiente en la base de datos master.
Como la implementación actual del evento SUBSCRIPTION no soporta con copy data y las
particiones están vacías, vamos a crear un slot de replicación lógica en la fuente. Esto se
hace fácilmente usando la cláusula CREATE SLOT. Esto significa que establecerá la posición LSN desde
la cual los cambios deben aplicarse al destino:
CREATE SUBSCRIPTION P_main_P0
CONNECTION 'port=7777 user=postgres dbname=master'
PUBLICATION P_main_P0 WITH (CREATE SLOT);
Es notable notar, que después de la creación de la suscripción notarás nuevos workers a cargo de enviar y recibir esos cambios, como se describe en la imagen arriba.
Como no es el alcance de este artículo, voy a omitir la explicación de los [logical|streaming] replication slots para mantener esto legible. Aunque, es un concepto central de la característica de replicación.
Consultando desde una base de datos externa
Este ejemplo no tiene otro propósito que mostrar una característica ya existente (aunque mejorada en versiones recientes) en acción. Pero muy especialmente voy a resaltar el INHERIT en una FOREIGN TABLE.
El siguiente DLL reside en una base de datos proxy, que no mantiene ningún dato de las particiones
y solo está destinada a mostrar algunas capacidades relativamente nuevas de Postgres.
CREATE EXTENSION postgres_fdw;
CREATE SERVER shard0 FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '7777',dbname 'shard0');
CREATE SERVER shard1 FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '8888',dbname 'shard1');
CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '9999',dbname 'shard2');
CREATE USER MAPPING FOR postgres SERVER shard0 OPTIONS(user 'postgres');
CREATE USER MAPPING FOR postgres SERVER shard1 OPTIONS(user 'postgres');
CREATE USER MAPPING FOR postgres SERVER shard2 OPTIONS(user 'postgres');
CREATE TABLE main (group_id char(2), payload jsonb);
CREATE FOREIGN TABLE main_shard0 (CHECK (group_id = 'P0'))INHERITS (main) SERVER shard0;
CREATE FOREIGN TABLE main_shard1 (CHECK (group_id = 'P1'))INHERITS (main) SERVER shard1;
CREATE FOREIGN TABLE main_shard2 (CHECK (group_id = 'P2'))INHERITS (main) SERVER shard2;
Como puedes apreciar, estamos combinando herencia, verificaciones de restricciones y foreign data wrappers
para evitar consultas a tablas remotas que no coinciden con el filtro group_id. También, adjunté
un EXPLAIN como prueba de que ninguna de las otras tablas foráneas ha sido examinada.
proxy=# SELECT * FROM main WHERE payload->>'key' = '847f5dd2-f892-4f56-b04a-b106063cfe0d' and group_id = 'P0';
group_id | payload
----------+--------------------------------------------------------------------
P0 | {"key": "847f5dd2-f892-4f56-b04a-b106063cfe0d", "topic": "PGSHARD", "offset": 47, "payload": "PXdmzb3EhEeNDdn5surg2VNmEdJoIys9", "partition": 0}
(1 rows)
proxy=# EXPLAIN SELECT *
FROM main
WHERE payload->>'key' = '847f5dd2-f892-4f56-b04a-b106063cfe0d'
AND group_id = 'P0';
QUERY PLAN
--------------------------------------------------------------------------------
Append (cost=0.00..135.07 rows=2 width=44)
-> Seq Scan on main (cost=0.00..0.00 rows=1 width=44)
Filter: ((group_id = 'P0'::bpchar) AND ((payload ->> 'key'::text) = '847f5dd2-f892-4f56-b04a-b106063cfe0d'::text))
-> Foreign Scan on main_shard0 (cost=100.00..135.07 rows=1 width=44)
Filter: ((payload ->> 'key'::text) = '847f5dd2-f892-4f56-b04a-b106063cfe0d'::text)
(5 rows)
¡Espero que te haya gustado el artículo!