Overhead estimado de postgres_fdw
¿Cuánto overhead se agrega usando postgres_fdw Foreign Data Wrappers?
Series: Postgres

Concepto
En el concepto actual, vamos a combinar herencia de tablas foráneas con
la extensión postgres_fdw, ambas siendo características ya disponibles desde la versión 9.5.
El particionamiento entre nodos permite una mejor localidad de datos y un modelo más escalable
que mantener particiones locales. Dicho esto, los datos se dividirán en varios
nodos y se organizarán usando una clave particular, que determinará en qué shard
se asignarán los datos. Para el POC actual, vamos a especificar el shardKey
, que es un tipo simple char(2).
Cómo se hacía esto antes
Hasta hoy, la única forma de realizar hallazgos sobre este método, era desde la capa de aplicación, emitiendo consultas directamente a los nodos manteniendo cierta forma determinística como {1} o usando una tabla de catálogo como {2} (NOTA: los ejemplos siguientes usan código pseudo).
query = "SELECT name,lastname FROM " + relation +
partition " WHERE " id =" + person_id
shard = query("SELECT shard FROM catalog WHERE key = " + person_id)
query = "SELECT name,lastname FROM " + relation + shard +
" WHERE " id =" + person_id
Cómo vamos a implementar esto ahora
Como las tablas foráneas (FT) no contienen datos por sí mismas, es posible mantener copias alrededor de todas las bases de datos involucradas y también en instancias separadas si esto es necesario.
Todas las operaciones contra la tabla se harán a través de la tabla padre de las tablas FT del árbol y Postgres mismo determinará la FT de destino usando la característica de exclusión de restricciones, que se detallará más adelante.
Para HA, estás limitado en los nodos de datos para implementar cualquier otra solución de replicación
disponible en la versión core. Para ser justos, 9.6 soporta streaming replication
y logical decoding, que es usado por la herramienta pglogical para proporcionar replicación lógica avanzada
por tabla.
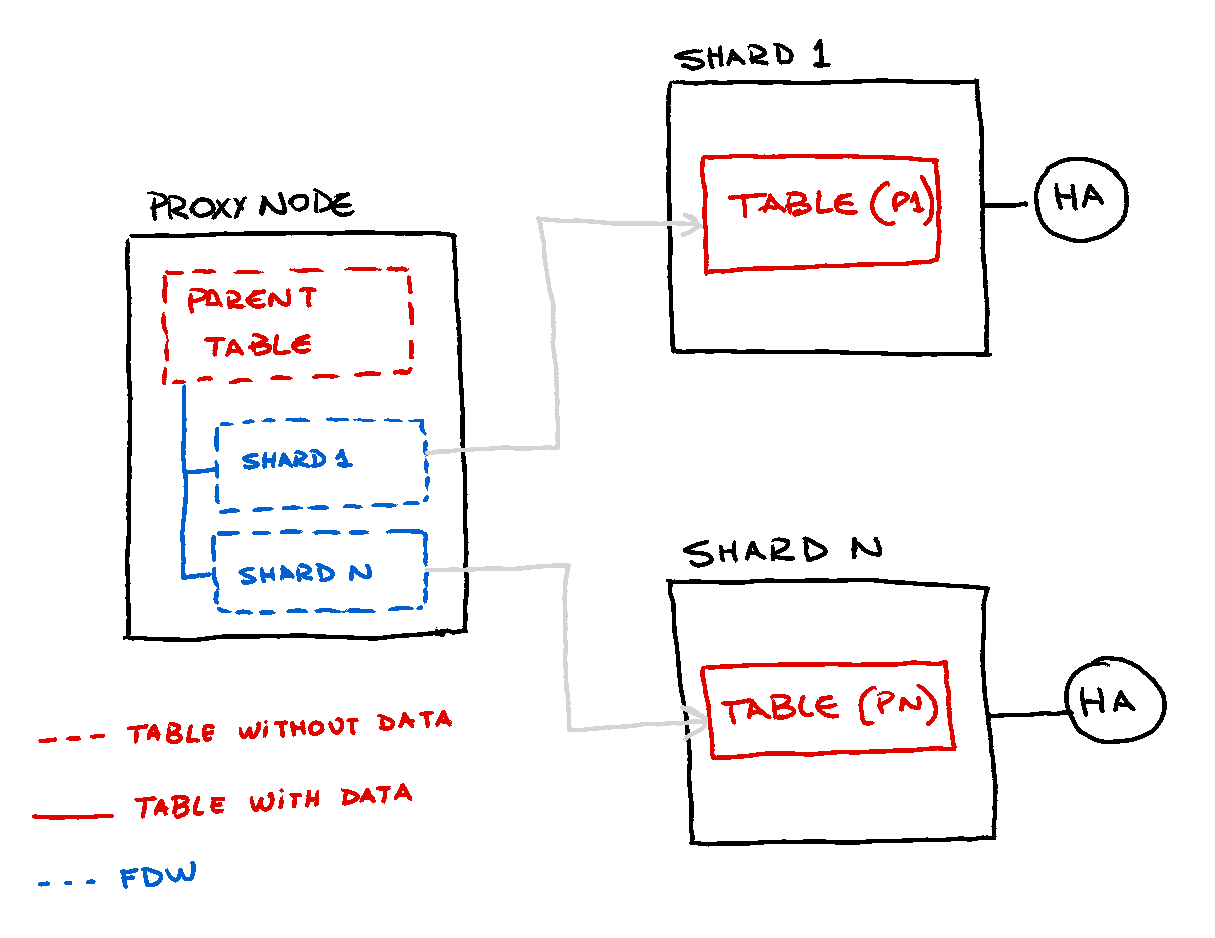
Tablas foráneas
Las tablas foráneas no contienen datos por sí mismas y solo hacen referencia a una tabla externa
en una base de datos Postgres diferente. Hay muchas extensiones diferentes
permitiendo tablas externas en diferentes soluciones de almacenamiento de datos, pero en este artículo particular
vamos a enfocarnos en postgres_fdw ya que queremos explorar más sobre
condition pushdowns, que hace que las consultas contra estas tablas sean más performantes
en consultas más complejas.
Un benchmark más extenso se puede encontrar en mi siguiente artículo.
El framework subyacente para los Foreign Data Wrappers, soporta tanto operaciones de lectura como
de escritura. postgres_fdw no es la excepción y también soporta condition
pushdown para evitar escaneos grandes en las tablas fuente.
En cada base de datos que contiene la FT, necesitas invocar la creación de la extensión:
CREATE EXTENSION postgres_fdw;
Las FT tienen dos elementos principales, necesarios para apuntar correctamente tanto en la fuente como en los privilegios de usuario. Si eres lo suficientemente paranoico, preferirás usar usuarios sin privilegios con grants limitados sobre las tablas que usas.
- Server
- User Mapping
{1}
CREATE SERVER shard1_main FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '5434',dbname 'shard1');
CREATE SERVER shard2_main FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '5435',dbname 'shard2');
-- Slaves
CREATE SERVER shard1_main_replica FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '7777',dbname 'shard1');
CREATE SERVER shard2_main_replica FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '8888',dbname 'shard2');
{2}
-- User mapping
CREATE USER MAPPING FOR postgres SERVER shard1_main OPTIONS(user 'postgres');
CREATE USER MAPPING FOR postgres SERVER shard2_main OPTIONS(user 'postgres');
CREATE USER MAPPING FOR postgres SERVER shard1_main_replica OPTIONS(user 'postgres');
CREATE USER MAPPING FOR postgres SERVER shard2_main_replica OPTIONS(user 'postgres');
La definición de FT es bastante directa si no queremos hacer ningún filtrado adicional de columnas:
CREATE TABLE main (shardKey char(2), key bigint, avalue text);
CREATE FOREIGN TABLE main_shard01
(CHECK (shardKey = '01'))
INHERITS (main)
SERVER shard1_main;
CREATE FOREIGN TABLE main_shard02
(CHECK (shardKey = '02'))
INHERITS (main)
SERVER shard2_main;
FDWs escribibles
Incluso si no recomiendo el siguiente enfoque, puede ser muy fácil centralizar las escrituras a los shards a través de la FT. Aunque, requiere codificar un trigger para manejar esto. Actualmente, el nivel mínimo de transacción para tablas foráneas es REPEATABLE READ, pero probablemente cambiará en versiones futuras.
Un enfoque muy simplista para un trigger INSERT sería como el siguiente:
CREATE OR REPLACE FUNCTION f_main_part() RETURNS TRIGGER AS
$FMAINPART$
DECLARE
partition_name text;
BEGIN
partition_name := 'main_shard' || NEW.shardKey;
EXECUTE 'INSERT INTO ' || quote_ident(partition_name) || ' SELECT ($1).*' USING NEW ;
RETURN NULL;
END;
$FMAINPART$ LANGUAGE plpgsql;
CREATE TRIGGER t_main BEFORE INSERT
ON main
FOR EACH ROW EXECUTE PROCEDURE f_main_part();
Datos en shards
Como los shards contienen datos, la declaración termina siendo una tabla común con el sufijo necesario para localización:
CREATE TABLE main_shard01( shardKey char(2),
key bigint,
avalue text,
CHECK(shardKey='01'));
CREATE INDEX ON main_shard01(key);
Una prueba simple podría hacerse emitiendo:
proxy=# INSERT INTO main
SELECT '0' || round(random()*1+1),i.i,random()::text
FROM generate_series(1,20000) i(i) ;
INSERT 0 0
Probablemente estés intuyendo que la declaración anterior inserta datos en ambos nodos, y el trigger derivará la fila en consecuencia al shard correspondiente.
NOTA: el número de shard se genera por
random()*1+1que redondea la salida entre 1 y 2.
Agárralos de las columnas ocultas
Consultar datos puede ser bastante transparente, como se muestra a continuación. El tableoid en este
caso particular puede ser engañoso, ya que los oid reportados son los de los nodos,
no la máquina local. Se usa solo para mostrar que son efectivamente diferentes
tablas:
proxy=# select tableoid,count(*) from main group by tableoid;
tableoid | count
----------+-------
33226 | 104
33222 | 96
(2 rows)
Por ejemplo, recuperar una sola fila es fácil como:
proxy=# SELECT avalue FROM main WHERE key = 1500 and shardKey = '01';
avalue
-------------------
0.971926014870405
(1 row)
Detrás de escena, la consulta empujada a los servidores remotos contiene el filtro correspondiente
((key = 1500)) y localmente, la exclusión de restricciones permite evitar escaneos adicionales
en la otra FT hija.
proxy=# explain (VERBOSE true)SELECT avalue
FROM main WHERE key = 1500
and shardKey = '01';
QUERY PLAN
--------------------------------------------------------------------------------
Append (cost=0.00..131.95 rows=2 width=32)
-> Seq Scan on public.main (cost=0.00..0.00 rows=1 width=32)
Output: main.avalue
Filter: ((main.key = 1500) AND (main.shardkey = '01'::bpchar))
-> Foreign Scan on public.main_shard01 (cost=100.00..131.95 rows=1 width=32)
Output: main_shard01.avalue
Remote SQL: SELECT avalue FROM public.main_shard01 WHERE ((key = 1500))
AND ((shardkey = '01'::bpchar))
(7 rows)
Incluso si no queremos proporcionar el shardKey, el filtro key se empujará a través de
todos los nodos shard. Si tus claves no son únicas entre shards, obtendrás un conjunto de resultados
de múltiples filas.
proxy=# explain (VERBOSE true)SELECT avalue FROM main WHERE key = 1500;
QUERY PLAN
--------------------------------------------------------------------------------
Append (cost=0.00..256.83 rows=15 width=32)
-> Seq Scan on public.main (cost=0.00..0.00 rows=1 width=32)
Output: main.avalue
Filter: (main.key = 1500)
-> Foreign Scan on public.main_shard01 (cost=100.00..128.41 rows=7 width=32)
Output: main_shard01.avalue
Remote SQL: SELECT avalue FROM public.main_shard01 WHERE ((key = 1500))
-> Foreign Scan on public.main_shard02 (cost=100.00..128.41 rows=7 width=32)
Output: main_shard02.avalue
Remote SQL: SELECT avalue FROM public.main_shard02 WHERE ((key = 1500))
(10 rows)
Consideraciones
Los Foreign Data Wrappers para Postgres son una gran extensión, pero viene con un precio con un overhead visible en cargas de trabajo transaccionales de alta intensidad.
¡Espero que te haya gustado el artículo!