Google Cloud TCP Internal Load Balancing con HTTP Health Checks en Terraform para servicios stateful
Mezclando protocolos para obtener balanceadores de red TCP con health checks HTTP.
Series: GCP
¡Feliz cumpleaños a mi querida esposa, Laura!

Consideraciones generales de integración de iLB y Terraform de GCP
Implementar un Internal Network Load Balancer en GCP a través de HCL (Terraform) requiere colocar un conjunto de recursos como piezas de lego, para hacerlo funcionar dentro de tu arquitectura.
Estamos excluyendo la opción external en este post ya que no se usa frecuentemente para servicios stateful o arquitecturas backend como bases de datos, que es la preocupación aquí. También, su implementación de Terraform varía fuertemente entre sí, p.ej. ciertos recursos como el Target Pool no se usan en el modo de esquema internal, haciendo que la configuración de autoscaling se vincule de manera diferente con su contraparte.
Se recomienda una lectura completa de la documentación de Google Cloud load balancing
Configurar un Load Balancer dependerá de qué recursos se hayan elegido para hacer girar los computes. Es decir,
google_compute_region_instance_group_manager, google_compute_instance_group_manager o computes únicos. En este post particular
me apegaré a google_compute_region_instance_group_manager por el bien de la abstracción.
El iLB como se muestra en el post actual, apunta a el nodo (a través del Backend Service) que devuelve
OK a su Health Check correspondiente (la mecánica interna de esto se comenta en la sección Health Check a continuación ).
Diferentemente de una flota stateless, para servicios stateful, solo un nodo puede mantener el leader lock para recibir transacciones de escritura.
DCS proporciona una forma de tener una configuración consistente y k/v sobre un cluster de nodos, centralizándola y proporcionando un consenso para ellos, evitando
escenarios de split-brain o configuración diferente en los nodos. Es decir, asegura que un único líder esté actuando en un cluster en
todo momento. Puede sonar muy simplista en la tarea, pero en entornos Cloud esto resulta ser crucial no solo en materia de consistencia,
sino también en el nivel de aprovisionamiento y configuración automática que hace una arquitectura resiliente y confiable.
DCS proporciona una forma de desplegar configuración consistente a todos los componentes relacionados en la arquitectura, no solo los Health Checks. p.ej. Los agentes de Consul pueden observar y aplicar configuración a ciertos servicios que necesitan refrescar endpoints o propagar una nueva configuración a todos los nodos.
Organización de recursos de componentes iLB
La vista de vuelo de la arquitectura expuesta del iLB se verá así en un diagrama:
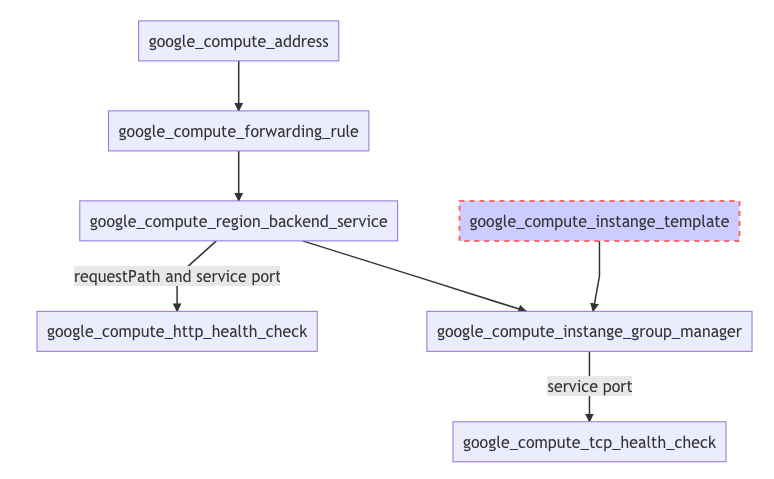
Nota: Ten en cuenta que el protocolo iLB sigue siendo TCP, aunque su health check (HC) está basado en HTTP. El otro HC, TCP, se usa para propósitos de autoscaling, y vuelve a hacer girar compute si el servicio API está caído.
Instance Managed Groups
No hay configuración iLB siendo parametrizada en este recurso, pero vale la pena mencionar que el bloque Autohealing apuntará a su Health Check específico para verificar si un servicio está disponible o no. Usualmente, para servicios stateless, podemos usar el mismo Health Check para el autohealing (o, al menos es funcional hacerlo); aunque, servicios stateful como bases de datos, pueden devolver código de respuesta no disponible (503) desde la API pero eso no significa que el servicio esté caído, ya que podría tener más estados complejos dependiendo de la ruta/método de solicitud (el servicio está arriba, pero no puede recibir escrituras).
Es importante definir un retraso inicial para verificar el servicio, especialmente en componentes stateful que podrían pasar cierto tiempo antes de que estén disponibles debido a transferencias de datos o aprovisionamiento. Durante el desarrollo, puedes querer eliminar este bloque, hasta que tus servicios estén disponibles, en caso contrario los computes serán destruidos en un bucle sin fin.
auto_healing_policies {
health_check = "${google_compute_health_check.tcp_hc.self_link}"
initial_delay_sec = "${var.initial_delay_sec}"
}
Como estamos configurando un iLB, google_compute_region_instance_group_manager ha sido elegido ya que es compatible con su
configuración. Este recurso gestiona computes a través de una región, a través de varias zonas de disponibilidad.
Health Checks
Considera una API a través del puerto 8008, ya sea que devuelva código de respuesta 503/200 sobre métodos master/replica.
La salida siguiente muestra las respuestas para ambos métodos sobre el mismo nodo master:
curl -sSL -D - http://127.0.0.1:8008/master
HTTP/1.0 200 OK
...
curl -sSL -D - http://127.0.0.1:8008/replica
HTTP/1.0 503 Service Unavailable
...
Estos métodos pueden usarse para la configuración del Backend Service para refrescar el nodo iLB que actúa como master o aquellos para réplicas (para iLB RO).
Es importante aclarar que crear Health Check no afecta los otros recursos a menos que estén vinculados. Preferirás definir este recurso incluso si tus servicios no están funcionando, ya que puedes conectarlo una vez que estén disponibles (como se mostrará en la sección Backend Service).
Hay un recurso legacy llamado google_compute_http_health_check,
que contiene la siguiente nota:
Nota: google_compute_http_health_check es un health check legacy. El más nuevo google_compute_health_check debería preferirse para todos los usos excepto Network Load Balancers que aún requieren la versión legacy.
Aunque, para iLB, es posible usar el recurso más nuevo (google_compute_health_check) y usar su bloque correspondiente
http_health_check/tcp_health_check en consecuencia:
resource "google_compute_health_check" "http_hc" {
name = "${var.name}-health-check"
check_interval_sec = 4
timeout_sec = 4
healthy_threshold = 2
unhealthy_threshold = 4
description = "este HC devuelve OK dependiendo del método"
http_health_check {
request_path = "/${var.reqpath}"
port = "${var.hcport}"
}
}
resource "google_compute_health_check" "tcp_hc" {
name = "${var.name}-health-check"
check_interval_sec = 4
timeout_sec = 4
healthy_threshold = 2
unhealthy_threshold = 4
description = "este HC es para autohealing y devuelve OK si el servicio está arriba"
tcp_health_check {
port = "${var.hcport}"
}
}
El health check de autohealing puede ser TCP o HTTP, solo asegúrate de que el método API HTTP devuelva no disponible solo si el servicio está completamente caído.
Otra recomendación es mantener tus umbrales e intervalos de verificación relativamente bajos, ya que puede amplificar el tiempo de inactividad por cada segundo agregado.
Más lectura disponible en Health Check/ Legacy Health Checks.
Recurso Backend Service (BackEnd del iLB)
Particularmente en este caso, el recurso correspondiente para google_compute_region_instance_group_manager es google_compute_region_backend_service.
Este recurso necesita:
- Qué instancias están en el tier backend (
${google_compute_region_instance_group_manager.instance_group_manager.instance_group}), - qué health check está en uso para determinar el nodo disponible (
${google_compute_health_check.http_hc.self_link}).
Un ejemplo de esto sería el siguiente:
resource "google_compute_region_backend_service" "instance_group_backendservice" {
name = "${var.name}-rig-bs"
description = "Region Instance Group Backend Service"
protocol = "TCP"
timeout_sec = 10
session_affinity = "NONE"
backend {
group = "${google_compute_region_instance_group_manager.instance_group_manager.instance_group}"
}
health_checks = ["${google_compute_health_check.http_hc.self_link}"]
}
El bloque backend proporciona las instancias creadas por google_compute_region_instance_group_manager y health_checks
apunta al HC predefinido arriba. Un backend service puede apuntar a varios Health Checks como se construye en google-lb-internal:
resource "google_compute_region_backend_service" "default" {
...
health_checks = ["${element(compact(concat(google_compute_health_check.tcp.*.self_link,google_compute_health_check.http.*.self_link)), 0)}"]
}
resource "google_compute_health_check" "tcp" {
count = "${var.http_health_check ? 0 : 1}"
project = "${var.project}"
name = "${var.name}-hc"
tcp_health_check {
port = "${var.health_port}"
}
}
resource "google_compute_health_check" "http" {
count = "${var.http_health_check ? 1 : 0}"
project = "${var.project}"
name = "${var.name}-hc"
http_health_check {
port = "${var.health_port}"
}
}
Este no es el caso que queremos configurar aquí, pero es una advertencia interesante si quieres agregar más verificaciones sobre más de un puerto.
Ten en cuenta que estamos configurando un Load Balancer interno, que es compatible con google_compute_region_backend_service ,
divergiendo del Load Balancer externo que requiere google_compute_backend_service. La diferencia es el nivel de abstracción
al aprovisionar nodos, que en el externo, necesitas terminar definiendo recursos más explícitamente que usando interno.
Nota: Los backend services de región solo pueden usarse cuando se usa load balancing interno. Para load balancing externo, usa google_compute_backend_service en su lugar. Terraform Doc
Forwarding Rule (FrontEnd del iLB)
La Forwarding Rule es un recurso que definirá las opciones del LB, en las que las más notables son:
load_balancing_schemeybackend_service.
El cambio de load_balancing_scheme requerirá cambios considerables en la arquitectura, así que necesitas
definir esto de antemano al hacer el diseño de tu infra. Respecto al backend_service, esto necesita apuntar al backend_service correspondiente
que haces girar para el Instance Managed Group.
resource "google_compute_forwarding_rule" "main_fr" {
project = "${var.project}"
name = "fw-rule-${var.name}"
region = "${var.region}"
network = "${var.network}"
backend_service = "${google_compute_region_backend_service.instance_group_backendservice.self_link}"
load_balancing_scheme = "INTERNAL"
ports = ["${var.forwarding_port_ranges}"]
ip_address = ["${google_compute_address.ilb_ip.address}"]
}
Es una práctica común predefinir una dirección compute para el iLB en lugar de dejar que GCP elija una por nosotros y, yendo más allá, puedes prevenir que este recurso sea destruido accidentalmente, ya que esta IP es un punto de entrada para tu aplicación y podría estar codificada en una pieza diferente de arquitectura:
resource "google_compute_address" "ilb_ip" {
name = "${var.name}-theIP"
project = "${var.project}"
region = "${var.region}"
address_type = "INTERNAL"
lifecycle {
prevent_destroy = true
}
}
¡No olvides las reglas de Firewall!
Todos los recursos anteriores son centrales para la configuración del iLB, aunque hay un recurso que aunque no es estrictamente
parte del componente, debe especificarse para permitir que los servicios y computes hablen entre sí. En este caso, los
source_ranges deben coincidir con la configuración de subred correspondiente de todos los recursos anteriores. Si estás en fase de desarrollo
, puedes usar 0.0.0.0/0 para abrir ampliamente la regla, aunque puedes querer especificar un rango de IP estrecho en producción.
resource "google_compute_firewall" "default-lb-fw" {
project = "${var.project}"
name = "${format("%v-%v-fw-ilb",var.name,count.index)}"
network = "${var.network}"
allow {
protocol = "tcp"
ports = ["${var.forwarding_port_ranges}"]
}
source_ranges = ["0.0.0.0/0"]
target_tags = ["${var.tags}"]
}
Más información sobre Google Cloud Load Balancer
Encontré un artículo interesante sobre Maglev, el Load Balancer de Infra de Google, que es una serie de posts explicando los internos, échale un vistazo.
¡Espero que te haya gustado este post, no dudes en señalar preguntas y comentarios!