This post has no intention to discuss what layout might be better in terms of
efficiency or effort. There are a considerable amount of great articles related
to all the analisys across different layouts, and even tools for ingesting text
and estimate the effort of typing the text for several layouts.
You’ll find this article more useful if you already decided to switch to Colemak, and
make it your primary layout. Personally, I have found very comfortable to write
in Dvorak, although there are some perks in Colemak regarding shortcut compatibility
among other benefits that made me do the choice. You can read a very interesting
comparision at this Xahlee post.
Why sampling is important and what you need to be aware of?
When dealing with very large amount of data, you probably want to run your
queries only for a smaller dataset in your current tables. Specially if your dataset
is not fitting in RAM.
MergeTree is the first and more advanced engine on Clickhouse that you want to try.
It supports indexing by Primary Key and it is mandatory to have a column of Date
type (used for automatic partitioning).
If you heard about Clickhouse and you are wondering how to test with your residing data in Redshift, here is a command
that will show you a few tips to make you speed up.
Update (July 4th): There is a serie of posts about Clickhouse vs Redshift comparisons, the first post is this one.
The standard wat to move your data out of Redshift is by using UNLOAD command,
which pushes the output into S3 files. Not surprisingly, Redshift does not support
COPY (<query>) TO STDOUT, which could make life easier (as it
Postgres version 8.0.2 based, quite ol’). Info about this, here.
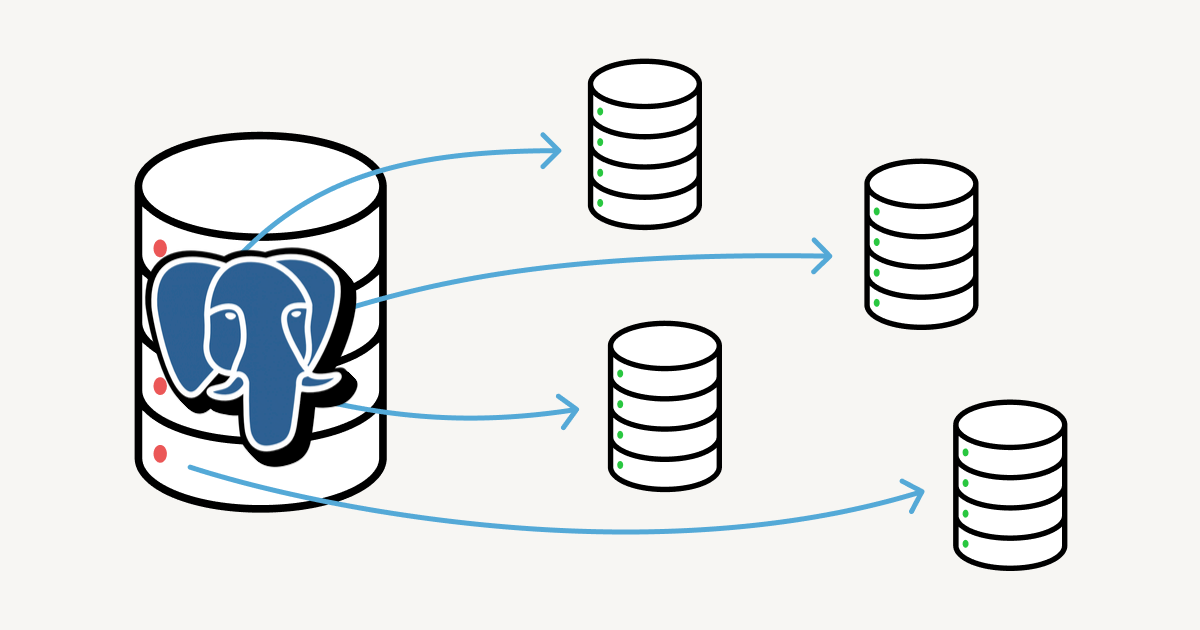
In the current concept, we are going to combine Foreign tables inheritance with
the postgres_fdw extension, both being already available features since 9.5 version.
Cross-node partitioning allows a better data locality and a more scalable model
than keeping local partitions. Being said, the data will be split into several
nodes and organized using a particular key, which will determine in which shard
data will be allocated. For the current POC, we are going to specify the shardKey
, which is a simple char(2) type.
In the current concept, we are going to combine Foreign tables inheritance with
the postgres_fdw extension, both being already available features since 9.5 version.
Cross-node partitioning allows a better data locality and a more scalable model
than keeping local partitions. Being said, the data will be split into several
nodes and organized using a particular key, which will determine in which shard
data will be allocated. For the current POC, we are going to specify the shardKey
, which is a simple char(2) type.
Apache Kafka and Postgres: Transaction and reporting capabilities
Apache Kafka is a well known distributed streaming platform for data processing
and consistent messaging. It allows you to consistently centralize data streams for
several purposes by consuming and producing them.
One of the examples of a nice implementation, is the Mozilla’s Data pipeline implementation,
particularly as it shows Kafka as an entry point of the data flow. This allows you to plug
new data stores bellow its stream, making it easy to use different data store formats (
such as DRBMS or Document, etc. ) for retrieving and writing data efficiently.