Highlighting Postgres 10 new features: Logical Replication and Partitioning.
And playing with retention policies.
Series: Postgres

Heya! I this article we are going to explore two of the major features commited in the upcoming PostgreSQL release: Logical Replication and Partitioning. Needeless to say that these features aren’t yet available in the stable release, so they are prune to change or extended.
Advertising warning! The current article is just a sneak peak of the upcoming talk Demystifying Logical Replication on PostgreSQL at Percona Live Santa Clara 2017. Get your tickets!
Logical Replication
The current logical replication mechanism is only row based. If you are around MySQL world you will notice that statement mode is not supported. If you are not familiar with the difference between the modes, TL;DR no matter how many rows are involved on the source query, they will be shipped as individual rows into the slaves. That is, a multi-row single statement as an INSERT in the source will produce an entry per modified row.
This is something you may want to have in consideration when doing bulk loads, as there are other tools/techniques that could be a better fit other than streaming everything from the master using the logical replication stream.
Generally speaking, it consist in three visible elements, also detailed on the image bellow:
- a Publication (source)
- a Subscription (consumer)
- and a Logical Replication Slot
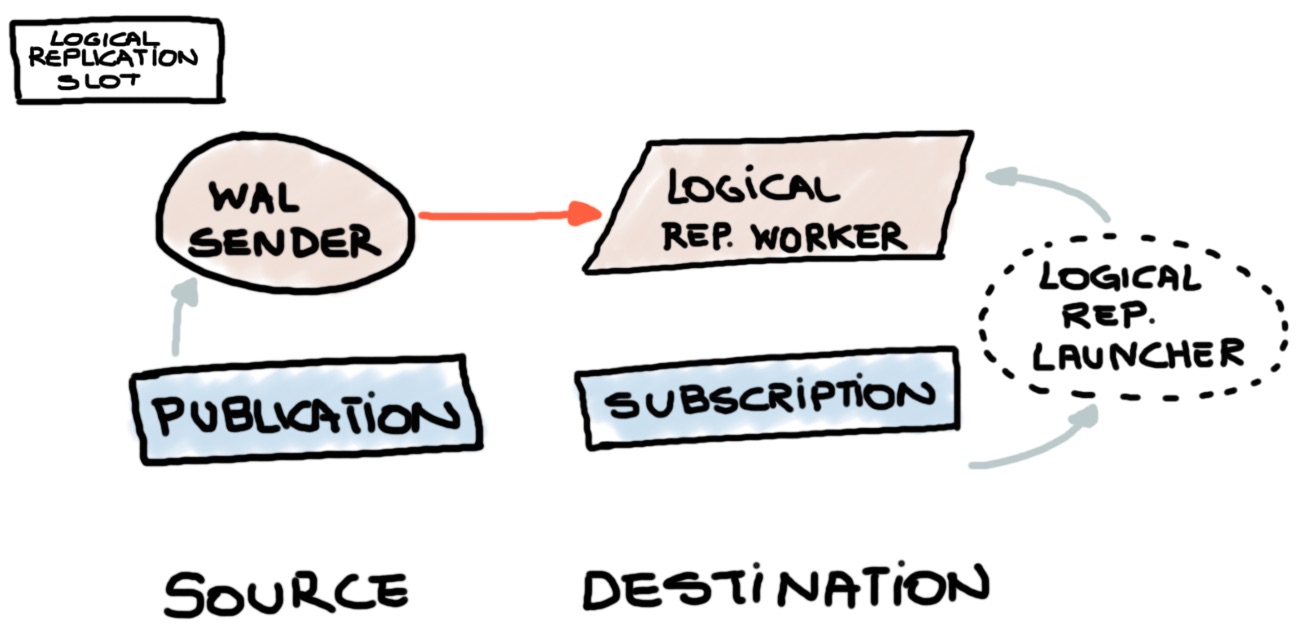
The most important and yet probably the most complex is the Logical Replication Slot.
The magic is done internally through the pgoutput plugin, which is the piece of code in charge
of translate the WAL records (pg_wal) into entries in the logical log (pg_logical).
The whole picture can be briefed like this: Consumers subscribe to a single Publisher using a slot, which contains the snapshot (LSN) of the database (the given point in time of the cluster). The slot will provide the information to the engine about the point in time since the changes must be replicated.
At this point, is important to note that the full feature is not entirely commited
and is expected to count with a WITH COPY DATA option at subscription event creation
in order to synchronize data from source. Currently, the patch has some bugs and is in process of review.
Although the whole topic is interesting, everything related to Logical Decoding will be ommited on this article. You can do more than just Postgres-to-Postgres replication.
Partitioning
In the past versions, it was possible to reach a very flexible partitioning approach by combining inheritance and multi-language based triggers. The current implementation does not allow to mix inheritance and partitioning but still has some flexibility for detaching and attaching partitions, using an explicit syntax.
In the current example, we are going to create three partitions with no data, just for keep focus only on the POC.
POC
The current concept works around on having slaves with a different retention policy of each partitioning by replicating each on different destinations and filtering the DELETE operations. As an addition, we are able to create a dummy structure, to point to each external partitioning for reporting or querying historic data.
The concept has three types of nodes/databases:
- A proxy (holding only Foreign Data Wrappers pointing to child tables in inheritance of a dummy table)
- A master (Containing all the partitions)
- Shard databases (Only holding the corresponding shard information)
More or less, using the commands on this article, you should end with a picture like this:
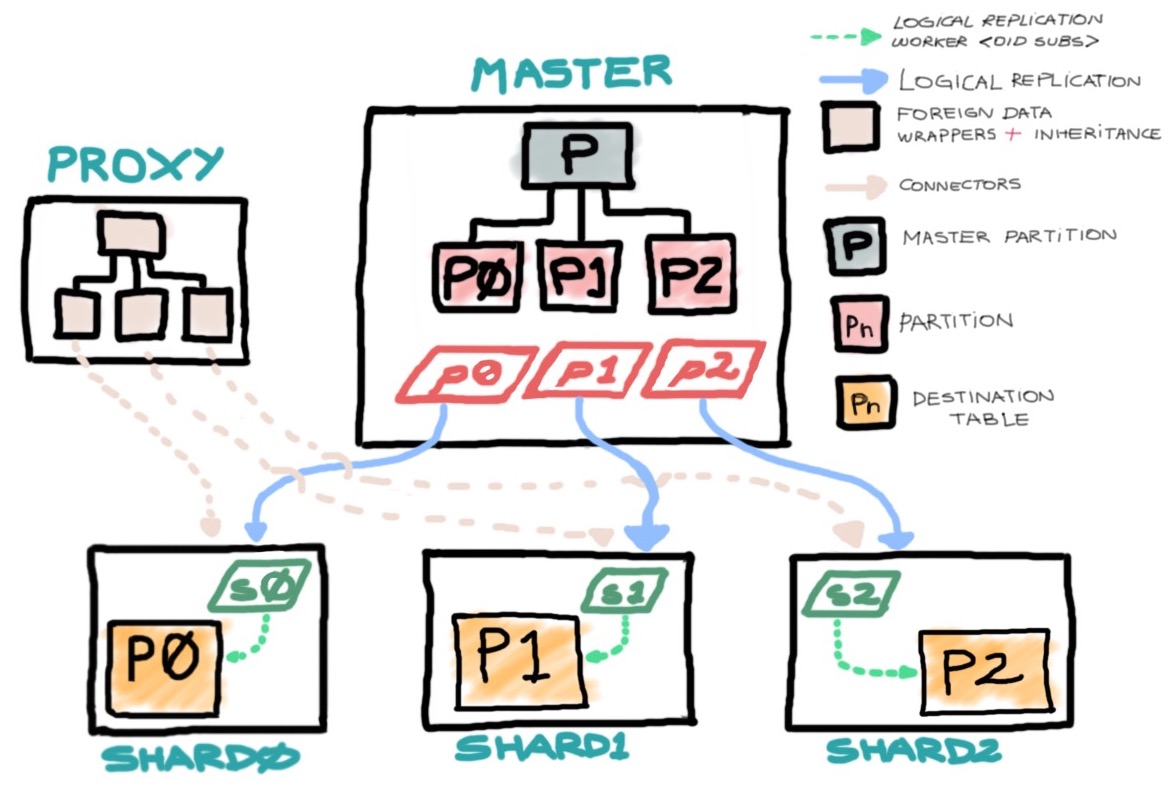
As you probably notice, by removing rows on the source database and filtering DELETE events at publishing time, you will end up with slaves holding more data, allowing larger timeframe queries. This is particularly useful for splitting BI queries in different layers depending on the date ranges specs, saving storage purposes on the source or keeping also a more maintenable table size. Queries against archiving can be done directly on the nodes or through the proxy implementation mentioned forward.
Partitioning on the source database/entrypoint
The master database will hold the definitions and the most recent data. The current concept, feeds from a Apache Kafka broker’s topic which is partitioned in three. We are going to feed this table with streams using COPY command. The article explaining how this was done is here.
The current master database tables DDL is:
CREATE TABLE main (group_id char(2), stamp timestamp without time zone DEFAULT now(), payload jsonb) PARTITION BY LIST(group_id);
CREATE TABLE main_shard0 PARTITION OF main
FOR VALUES IN ('P0');
CREATE TABLE main_shard1 PARTITION OF main
FOR VALUES IN ('P1');
CREATE TABLE main_shard2 PARTITION OF main
FOR VALUES IN ('P2');
CREATE INDEX ix_main_shard_p0_key ON main_shard0 (stamp,(payload->>'key'));
CREATE INDEX ix_main_shard_p1_key ON main_shard1 (stamp,(payload->>'key'));
CREATE INDEX ix_main_shard_p2_key ON main_shard2 (stamp,(payload->>'key'));
The group_id column holds the topic’s partition number from which the data has
been consumed from the Kafka broker.
Now, it is time to publish them within the corresponding event filtering. At this point, there isn’t associated any replication slot with the publications:
CREATE PUBLICATION P_main_P0 FOR TABLE main_shard0 WITH (NOPUBLISH DELETE);
CREATE PUBLICATION P_main_P1 FOR TABLE main_shard1 WITH (NOPUBLISH DELETE);
CREATE PUBLICATION P_main_P2 FOR TABLE main_shard2 WITH (NOPUBLISH DELETE);
By the current state of the last commits on PostgreSQL, Logical Replication does not support
filtering by column value as pglogical tool does. Even tho is possible to filter by
event statement, which still quite useful for our purpose (NOPUBLISH|PUBLISH) as
described above.
Creating the nodes
The table definition on the nodes should be straightforward:
CREATE TABLE main_shard0 (group_id char(2), stamp timestamp without time zone, payload jsonb);
We now need to create the SUBSCRIPTION to feed from the corresponding PUBLICATION on the master database.
As the current implementation of the SUBSCRIPTION event does not support with copy data and the
partitions are empty, we are going to create a logical replication slot on the source. This is
easily done by using the CREATE SLOT clause. This means that it will set the LSN position from
which the changes must be applied to the destination:
CREATE SUBSCRIPTION P_main_P0
CONNECTION 'port=7777 user=postgres dbname=master'
PUBLICATION P_main_P0 WITH (CREATE SLOT);
It is remarkable to note, that after subscription creation you will notice new workers in charge of sending and receiving those changes, as described in the image above.
As it is not the scope of this article, I’m going to skip the explanation of the [logical|streaming] replication slots in order to keep this readable. Although, it is a core concept of the replication feature.
Querying from an external database
This example has no other purpose than to show an already existent feature (although improved in recent versions) in action. But very specially I’m going to highlight the INHERIT on a FOREIGN TABLE.
The following DLL resides on a proxy database, which does not hold any data of the partitions
and is only intended to show some relatively new Postgres’ capabilities.
CREATE EXTENSION postgres_fdw;
CREATE SERVER shard0 FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '7777',dbname 'shard0');
CREATE SERVER shard1 FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '8888',dbname 'shard1');
CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '9999',dbname 'shard2');
CREATE USER MAPPING FOR postgres SERVER shard0 OPTIONS(user 'postgres');
CREATE USER MAPPING FOR postgres SERVER shard1 OPTIONS(user 'postgres');
CREATE USER MAPPING FOR postgres SERVER shard2 OPTIONS(user 'postgres');
CREATE TABLE main (group_id char(2), payload jsonb);
CREATE FOREIGN TABLE main_shard0 (CHECK (group_id = 'P0'))INHERITS (main) SERVER shard0;
CREATE FOREIGN TABLE main_shard1 (CHECK (group_id = 'P1'))INHERITS (main) SERVER shard1;
CREATE FOREIGN TABLE main_shard2 (CHECK (group_id = 'P2'))INHERITS (main) SERVER shard2;
As you may appreciate, we are combining inheritance, constraint checks and foreign data wrappers
for avoiding queries to remote tables that do not match the group_id filter. Also, I attached
an EXPLAIN as proof that none of the other foreign tables have been examined.
proxy=# SELECT * FROM main WHERE payload->>'key' = '847f5dd2-f892-4f56-b04a-b106063cfe0d' and group_id = 'P0';
group_id | payload
----------+--------------------------------------------------------------------
P0 | {"key": "847f5dd2-f892-4f56-b04a-b106063cfe0d", "topic": "PGSHARD", "offset": 47, "payload": "PXdmzb3EhEeNDdn5surg2VNmEdJoIys9", "partition": 0}
(1 rows)
proxy=# EXPLAIN SELECT *
FROM main
WHERE payload->>'key' = '847f5dd2-f892-4f56-b04a-b106063cfe0d'
AND group_id = 'P0';
QUERY PLAN
--------------------------------------------------------------------------------
Append (cost=0.00..135.07 rows=2 width=44)
-> Seq Scan on main (cost=0.00..0.00 rows=1 width=44)
Filter: ((group_id = 'P0'::bpchar) AND ((payload ->> 'key'::text) = '847f5dd2-f892-4f56-b04a-b106063cfe0d'::text))
-> Foreign Scan on main_shard0 (cost=100.00..135.07 rows=1 width=44)
Filter: ((payload ->> 'key'::text) = '847f5dd2-f892-4f56-b04a-b106063cfe0d'::text)
(5 rows)
Hope you liked the article!