Simple and manual sharding on PostgreSQL.
Foreign Data Wrappers inheritance.
Series: Postgres
Concept
In the current concept, we are going to combine Foreign tables inheritance with
the postgres_fdw extension, both being already available features since 9.5 version.
Cross-node partitioning allows a better data locality and a more scalable model
than keeping local partitions. Being said, the data will be split into several
nodes and organized using a particular key, which will determine in which shard
data will be allocated. For the current POC, we are going to specify the shardKey
, which is a simple char(2) type.
How this was done before
Until today, the only way to perform findings over this method, was from the application layer, by issuing queries directly to the nodes by keeping certain deterministic way as or using a catalog table:
NOTE: the bellow examples are using pseudo code.
query = "SELECT name,lastname FROM " +
relation + partition + " WHERE " id =" + person_id
shard = query("SELECT shard FROM catalog WHERE key = " + person_id)
query = "SELECT name,lastname FROM " + relation + shard +
" WHERE " id =" + person_id
How we are going to implement this now
As foreign tables (FT) does not hold any data, it is possible to keep copies aroud all the databases involved and also in separated instances if this is necessary.
All the operations against the table will be done through the parent table of the FT tree tables and Postgres itself will determine the destination FT using the constraint exclusion feature, which will be detailed further.
For HA, you are limited on the data nodes to implement any other replication
solution available in the core version. To be fair, 9.6 supports streaming replication
and logical decoding, which is used by the pglogical tool for providing advanced
logical replication per table basis.
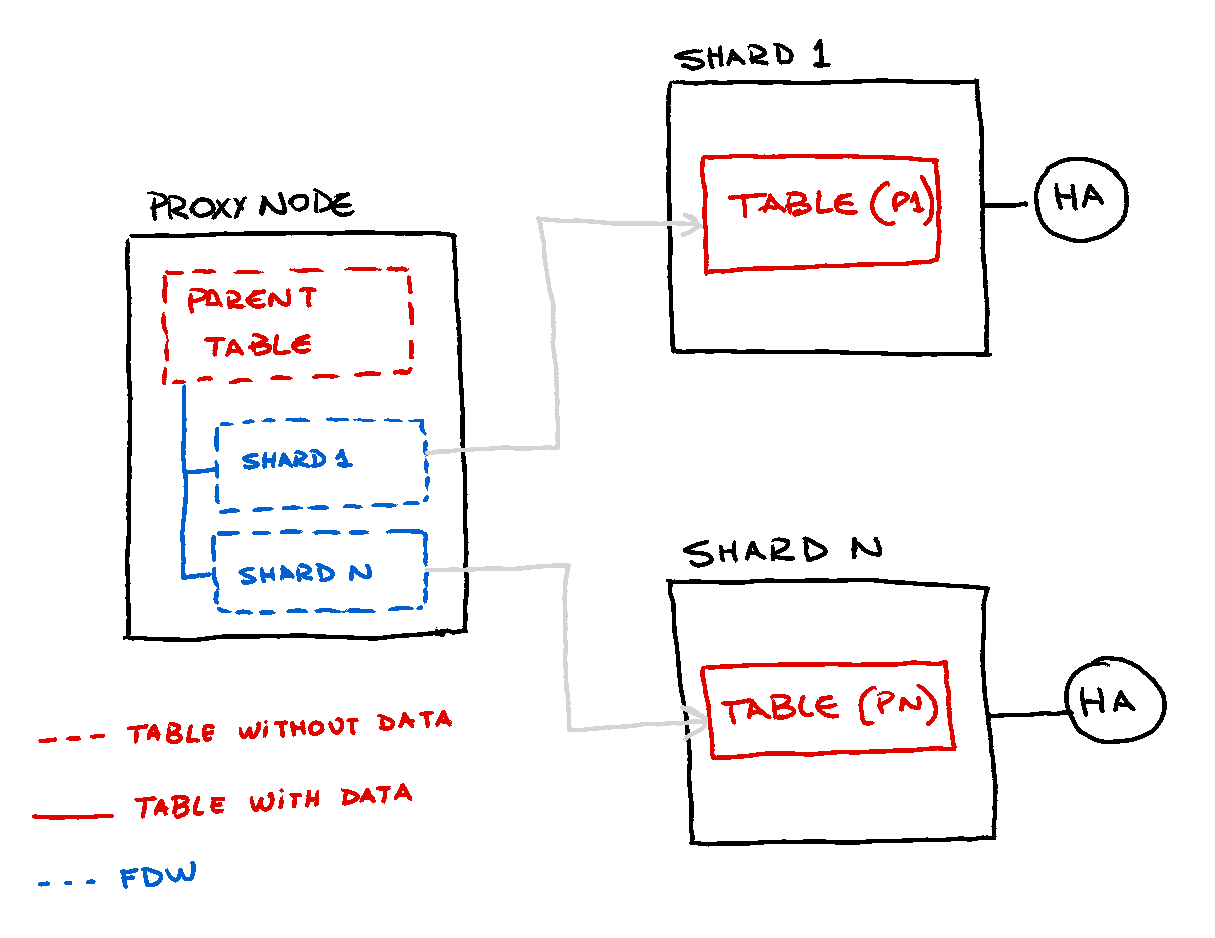
Foreign tables
Foreign tables do not contain data by itselves and they only reference to a external
table on a different Postgres database. There are plenty of different extensions
allowing external tables on different data store solutions, but in this particular
article we are going to focus on postgres_fdw as we want to explore more about
condition pushdowns, which makes queries against these tables more performant
on more complex queries.
A more extensive benchmark can be found at my next article.
The framework underlying for the Foreign Data Wrappers, support both reads and
write operations. postgres_fdw is not the exception and does also support condition
pushdown for avoiding large scans on the source tables.
On each database holding the FT, you need to invoke the extension creation:
CREATE EXTENSION postgres_fdw;
FT have two main elements,necessary to point correctly both in source as in user privileges. If you are paranoic enough, you’ll prefer to use unprivileged users with limited grants over the tables that you use.
CREATE SERVER shard1_main FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '5434',dbname 'shard1');
CREATE SERVER shard2_main FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '5435',dbname 'shard2');
-- Slaves
CREATE SERVER shard1_main_replica FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '7777',dbname 'shard1');
CREATE SERVER shard2_main_replica FOREIGN DATA WRAPPER postgres_fdw
OPTIONS(host '127.0.0.1',port '8888',dbname 'shard2');
-- User mapping
CREATE USER MAPPING FOR postgres SERVER shard1_main OPTIONS(user 'postgres');
CREATE USER MAPPING FOR postgres SERVER shard2_main OPTIONS(user 'postgres');
CREATE USER MAPPING FOR postgres SERVER shard1_main_replica OPTIONS(user 'postgres');
CREATE USER MAPPING FOR postgres SERVER shard2_main_replica OPTIONS(user 'postgres');
The FT definition is indeed pretty straightforward if we don’t want to do any further column filtering:
CREATE TABLE main (shardKey char(2), key bigint, avalue text);
CREATE FOREIGN TABLE main_shard01
(CHECK (shardKey = '01'))
INHERITS (main)
SERVER shard1_main;
CREATE FOREIGN TABLE main_shard02
(CHECK (shardKey = '02'))
INHERITS (main)
SERVER shard2_main;
Writable FDWs
Even if I don’t recommend the following approach, it can be very easy to centralize the writes to the shards through the FT. Although, it requires to code a trigger for managing this. Currently, the minimum transaction level for foreign tables is REPEATABLE READ, but it will probably change in future versions.
A very simplistic approach for an INSERT trigger will be like bellow:
CREATE OR REPLACE FUNCTION f_main_part() RETURNS TRIGGER AS
$FMAINPART$
DECLARE
partition_name text;
BEGIN
partition_name := 'main_shard' || NEW.shardKey;
EXECUTE 'INSERT INTO ' || quote_ident(partition_name) || ' SELECT ($1).*' USING NEW ;
RETURN NULL;
END;
$FMAINPART$ LANGUAGE plpgsql;
CREATE TRIGGER t_main BEFORE INSERT
ON main
FOR EACH ROW EXECUTE PROCEDURE f_main_part();
Data on shards
As shards contain data, the declaration ends up to be a common table within the necessary suffix for localization:
CREATE TABLE main_shard01( shardKey char(2),
key bigint,
avalue text,
CHECK(shardKey='01'));
CREATE INDEX ON main_shard01(key);
A simple test could be done by issuing:
proxy=# INSERT INTO main
SELECT '0' || round(random()*1+1),i.i,random()::text
FROM generate_series(1,20000) i(i) ;
INSERT 0 0
You probably are intuiting that the above statement inserts data on both nodes, and the trigger will derive the row accordingly to the corresponding shard.
NOTE: the shard number is generated by
random()*1+1which output rounds between 1 and 2.
Grab them from the hidden columns
Querying data can be nicely transparent, as shown bellow. The tableoid in this
particular case can be misleading, as the oid reported are those from the nodes,
not the local machine. It is used just to show that they’re effectively different
tables:
proxy=# select tableoid,count(*) from main group by tableoid;
tableoid | count
----------+-------
33226 | 104
33222 | 96
(2 rows)
For example, retrieving a single row is easy as:
proxy=# SELECT avalue FROM main WHERE key = 1500 and shardKey = '01';
avalue
-------------------
0.971926014870405
(1 row)
Behind the scenes, the pushed query to the remote servers contains the corresponding
filter ((key = 1500)) and locally, the constraint exclusion allows to avoid further
scans into the other child FT.
proxy=# explain (VERBOSE true)SELECT avalue
FROM main WHERE key = 1500
and shardKey = '01';
QUERY PLAN
--------------------------------------------------------------------------------
Append (cost=0.00..131.95 rows=2 width=32)
-> Seq Scan on public.main (cost=0.00..0.00 rows=1 width=32)
Output: main.avalue
Filter: ((main.key = 1500) AND (main.shardkey = '01'::bpchar))
-> Foreign Scan on public.main_shard01 (cost=100.00..131.95 rows=1 width=32)
Output: main_shard01.avalue
Remote SQL: SELECT avalue FROM public.main_shard01 WHERE ((key = 1500))
AND ((shardkey = '01'::bpchar))
(7 rows)
Even if we don’t want to provide the shardKey, the key filter will be pushed across
all the shard nodes. If your keys aren’t unique across shards, you’ll get a multi-row
result set.
proxy=# explain (VERBOSE true)SELECT avalue FROM main WHERE key = 1500;
QUERY PLAN
--------------------------------------------------------------------------------
Append (cost=0.00..256.83 rows=15 width=32)
-> Seq Scan on public.main (cost=0.00..0.00 rows=1 width=32)
Output: main.avalue
Filter: (main.key = 1500)
-> Foreign Scan on public.main_shard01 (cost=100.00..128.41 rows=7 width=32)
Output: main_shard01.avalue
Remote SQL: SELECT avalue FROM public.main_shard01 WHERE ((key = 1500))
-> Foreign Scan on public.main_shard02 (cost=100.00..128.41 rows=7 width=32)
Output: main_shard02.avalue
Remote SQL: SELECT avalue FROM public.main_shard02 WHERE ((key = 1500))
(10 rows)
Considerations
Foreign Data Wrappers for Postgres are such a great extension, but it comes at a price with a visible overhead in high intensive transactional workloads.
Hope you liked the article!