Google Cloud TCP Internal Load Balancing with HTTP Health Checks in Terraform for stateful services
Mixing protocols for getting TCP network balancers with HTTP health checks.
Series: GCP
Happy birthday to my lovely wife, Laura!

GCP iLB and Terraform integration general considerations
Implementing an Internal Network Load Balancer in GCP through HCL (Terraform) requires to place a set of resources as lego pieces, in order to make it work inside your architecture.
We are excluding the external option in this post as it is not oftenly being use for stateful services or backend architectures such as databases, which is the concern here. Also, its Terraform implementation vary in between strongly, e.g. certain resources such as the Target Pool aren’t used in the internal scheme mode, making the autoscaling configuration tied differently with its counterpart.
It is recommended a full read of Google Cloud load balancing documentation
Setting up a Load Balancer will depend on which resources have been choose for spinning the computes. That is,
google_compute_region_instance_group_manager, google_compute_instance_group_manager or single computes. In this particular post
I’m going to stick to google_compute_region_instance_group_manager for the sake of abstraction.
The iLB as shown in the current post, points to the node (through the Backend Service) that return
OK to its corresponding Health Check (internal mechanics of this are commented in the Health Check section bellow ).
Differently from a stateless fleet, for stateful services, only one node can hold the leader lock for receiving writting transactions.
DCS provides a way to have a consistent configuration and k/v over a cluster of nodes, centralizing it and providing a consensus for them, avoiding
split-brain scenarios or different configuration in the nodes. That is, it ensures that a single leader is acting in a cluster at
all time. It may sound very simplistic at the task, but on Cloud environments this turn out to be crucial not only in the matter of consistency,
but also in the level of provisioning and automatic configuration which makes an architecture resilient and reliable.
DCS provides a way to deploy consistent configuration to all the components related in the architecture, not only the Health Checks. e.g. Consul agents can watch and apply configuration to certain services that need to refresh endpoints or propagate a new configuration to all nodes.
Resource organization of iLB components
The flight view of exposed architecture of the iLB will look like this in a diagram:
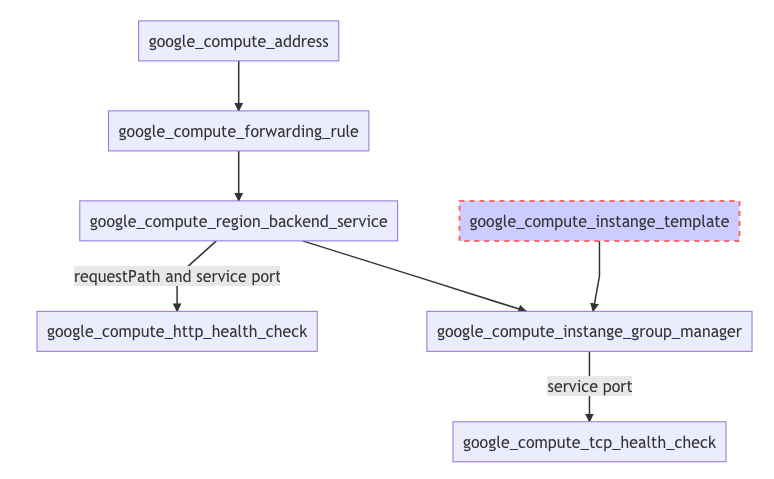
Note: Keep in mind that the iLB protocol is still TCP, although its health check (HC) is HTTP based. The other HC, TCP, is used for autoscaling purposes, and it re-spins compute if the API service is down.
Instance Managed Groups
There is no iLB configuration being parametrized in this resource, but it worth mentioning that the Autohealing block will point to its specific Health Check to check wether a service is available or not. Usually, for stateless services, we can use the same Health Check for the autohealing (or, at least is functional to do so); although, stateful services such databases, can return not available (503) response code from the API but it does not mean that the service is down, as it might have more complex statuses depending the request path/method (service is up, but can’t receive writes).
It is important to define an initial delay for checking the service, specially on stateful components that could spend certain time before they are available due to data transfers or provisioning. During development, you may want to wipe this block out, until your services are available, in the contrary the computes will be destroy in an endless loop.
auto_healing_policies {
health_check = "${google_compute_health_check.tcp_hc.self_link}"
initial_delay_sec = "${var.initial_delay_sec}"
}
As we are setting up an iLB, google_compute_region_instance_group_manager has been choose as it is compatible with its
setup. This resource manages computes across a region, through several availability zones.
Health Checks
Consider an API through port 8008, wether it returns 503/200 response over master/replica methods.
The bellow output shows the responses for both methods over the same master node:
curl -sSL -D - http://127.0.0.1:8008/master
HTTP/1.0 200 OK
...
curl -sSL -D - http://127.0.0.1:8008/replica
HTTP/1.0 503 Service Unavailable
...
These methods can be used for the Backend Service configuration for refreshing the iLB node that act as master or those for replicas (for RO iLB).
It is important to clarify that creating Health Check does not affect the other resources unless linked. You will prefer to define this resource even if your services aren’t up and running, as you can plug it once they are available (as it will be shown in the Backend Service section).
There is a legacy resource called google_compute_http_health_check,
which contains the following note:
Note: google_compute_http_health_check is a legacy health check. The newer google_compute_health_check should be preferred for all uses except Network Load Balancers which still require the legacy version.
Even tho, for iLB, it is possible to use the newer resource (google_compute_health_check) and use its corresponding
http_health_check/tcp_health_check block accordingly:
resource "google_compute_health_check" "http_hc" {
name = "${var.name}-health-check"
check_interval_sec = 4
timeout_sec = 4
healthy_threshold = 2
unhealthy_threshold = 4
description = "this HC returns OK depending on the method"
http_health_check {
request_path = "/${var.reqpath}"
port = "${var.hcport}"
}
}
resource "google_compute_health_check" "tcp_hc" {
name = "${var.name}-health-check"
check_interval_sec = 4
timeout_sec = 4
healthy_threshold = 2
unhealthy_threshold = 4
description = "this HC is for autohealing and returns OK if service is up"
tcp_health_check {
port = "${var.hcport}"
}
}
The autohealing health check can either be TCP or HTTP, just make sure that the HTTP API method returns not available only if the service is completely down.
Another recommendation is to keep your thresholds and check intervals relatively low, as it can amplificate the downtime per each added second.
More read available at Health Check/ Legacy Health Checks.
Backend Service Resource (BackEnd of the iLB)
Particularly in this case, the corresponding resource for google_compute_region_instance_group_manager is google_compute_region_backend_service.
This resource needs:
- Which instances are in the backend tier (
${google_compute_region_instance_group_manager.instance_group_manager.instance_group}), - which health check is in use to determine the available node (
${google_compute_health_check.http_hc.self_link}).
An example of this would be the following:
resource "google_compute_region_backend_service" "instance_group_backendservice" {
name = "${var.name}-rig-bs"
description = "Region Instance Group Backend Service"
protocol = "TCP"
timeout_sec = 10
session_affinity = "NONE"
backend {
group = "${google_compute_region_instance_group_manager.instance_group_manager.instance_group}"
}
health_checks = ["${google_compute_health_check.http_hc.self_link}"]
}
The backend block provices the instances created by google_compute_region_instance_group_manager and health_checks
point to the predefined HC above. One backend service can point to several Health Checks like built in the google-lb-internal:
resource "google_compute_region_backend_service" "default" {
...
health_checks = ["${element(compact(concat(google_compute_health_check.tcp.*.self_link,google_compute_health_check.http.*.self_link)), 0)}"]
}
resource "google_compute_health_check" "tcp" {
count = "${var.http_health_check ? 0 : 1}"
project = "${var.project}"
name = "${var.name}-hc"
tcp_health_check {
port = "${var.health_port}"
}
}
resource "google_compute_health_check" "http" {
count = "${var.http_health_check ? 1 : 0}"
project = "${var.project}"
name = "${var.name}-hc"
http_health_check {
port = "${var.health_port}"
}
}
This is not the case we want to configure here, but is an interesting heads up if you want to add more checks over more than one port.
Keep in mind that we are setting an internal Load Balancer, which is compatible with google_compute_region_backend_service ,
diverging from the external Load Balancer that require google_compute_backend_service. The difference is the level of the abstraction
when provisioning nodes, which in the external, you need to end up defining resources more explicitely than using internal.
Note: Region backend services can only be used when using internal load balancing. For external load balancing, use google_compute_backend_service instead. Terraform Doc
Forwarding Rule (FrontEnd of the iLB)
The Forwarding Rule is a resource that will define the LB options, in which the most noticeable are:
load_balancing_schemeandbackend_service.
The load_balancing_scheme change will require considerable changes on the architecture, so you need to
define this before hand when blackboarding your infra. Regarding the backend_service, this needs to point to the corresponding
backend_service than you spin for the Instance Managed Group.
resource "google_compute_forwarding_rule" "main_fr" {
project = "${var.project}"
name = "fw-rule-${var.name}"
region = "${var.region}"
network = "${var.network}"
backend_service = "${google_compute_region_backend_service.instance_group_backendservice.self_link}"
load_balancing_scheme = "INTERNAL"
ports = ["${var.forwarding_port_ranges}"]
ip_address = ["${google_compute_address.ilb_ip.address}"]
}
It is a common practice to predefine a compute address for the iLB instead leaving GCP choose one for us and, going further, you can prevent this resource to be destroyed accidentaly, as this IP is an entrypoint for your application and might be coded in a different piece of architecture:
resource "google_compute_address" "ilb_ip" {
name = "${var.name}-theIP"
project = "${var.project}"
region = "${var.region}"
address_type = "INTERNAL"
lifecycle {
prevent_destroy = true
}
}
Don’t forget the Firewall Rules!
All the above resources are core to the iLB setup, although there is one resource that even tho isn’t strictly
part of the component, it must be specified to allow services and computes talk to each other. In this case, the
source_ranges should match the corresponding subnet setup of all the above resources. If you happen to be in development
phase, you can use 0.0.0.0/0 for wide opening the rule, although you may want to specify a narrow IP range in production.
resource "google_compute_firewall" "default-lb-fw" {
project = "${var.project}"
name = "${format("%v-%v-fw-ilb",var.name,count.index)}"
network = "${var.network}"
allow {
protocol = "tcp"
ports = ["${var.forwarding_port_ranges}"]
}
source_ranges = ["0.0.0.0/0"]
target_tags = ["${var.tags}"]
}
More information about Google Cloud Load Balancer
I found an interesting article about Maglev, the Google’s Infra Load Balancer, which a series of posts explaining the internals, check it out.
Hope you liked this post, do not hesitate to point questions and comments!